There is a dataframe:
df = pd.DataFrame.from_dict({
'A': ['A1','A1','A1','A1','A2','A2','A2','A2'],
'B': ['B1','B1','B2','B2','B3','B3','B4','B4'],
'C': ['one','two','one','two','one','two','one','two'],
'D': [0, 0, np.nan, 1, 0, np.nan, 1, 1],
'E': [1, 1, np.nan, 1, 0, np.nan, 1, 1]
})
So, as a table it looks like this:
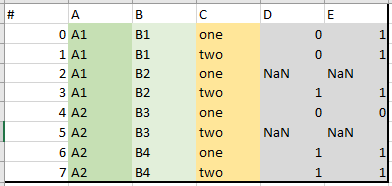
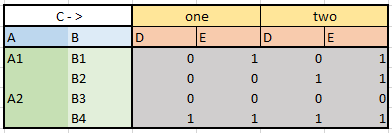
I try to group it by A and B and move column C to header, so columns will rename to ('one', 'D'), ('one', 'E'), ('two', 'D'), ('two', 'E') and it will take the following look:
To achieve this I tried pivot_table and group unstack methods:
# Method 1
df.pivot_table(index=['A', 'B'], columns='C', values=['D', 'E'], aggfunc='sum', fill_value=0)
# Method 2
df.groupby(['A', 'B', 'C']).agg('sum').unstack(level=['D', 'E'])
Both methods return me the same result, where values as column names are at the very top:
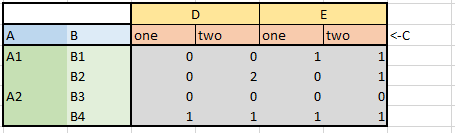
How can columns layers be moved or pivot table created with values on the very low column level?
Or more precise question: how to get dataframe from image 2 instead of dataframe from image 3 from df?
CodePudding user response:
If using pivoting is possible add DataFrame.swaplevel and DataFrame.sort_index:
df = (df.pivot_table(index=['A', 'B'],
columns='C',
values=['D', 'E'],
aggfunc='sum', fill_value=0)
.swaplevel(axis=1)
.sort_index(axis=1))
print (df)
C one two
D E D E
A B
A1 B1 0 1 0 1
B2 0 0 1 1
A2 B3 0 0 0 0
B4 1 1 1 1
Or if use aggregation sum is possible use DataFrame.stack with Series.unstack:
df = (df.groupby(['A', 'B', 'C']).sum()
.stack()
.unstack([-2,-1])
)
print (df)
C one two
D E D E
A B
A1 B1 0.0 1.0 0.0 1.0
B2 0.0 0.0 1.0 1.0
A2 B3 0.0 0.0 0.0 0.0
B4 1.0 1.0 1.0 1.0