This question here is a follow up question occurred in the comments of 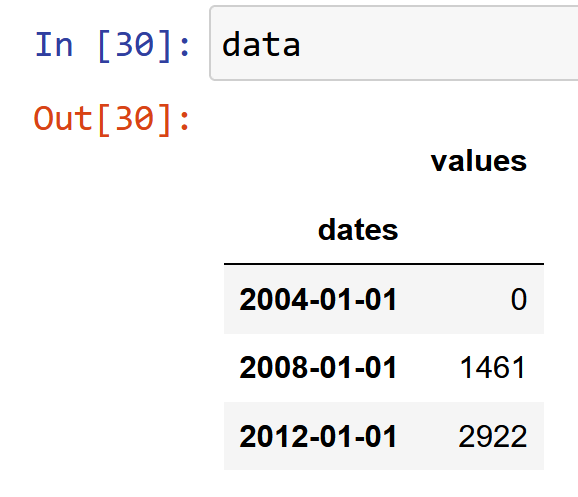
Now, when I resample and interpolate by
data.resample('A').mean().interpolate()
I obtain the following:
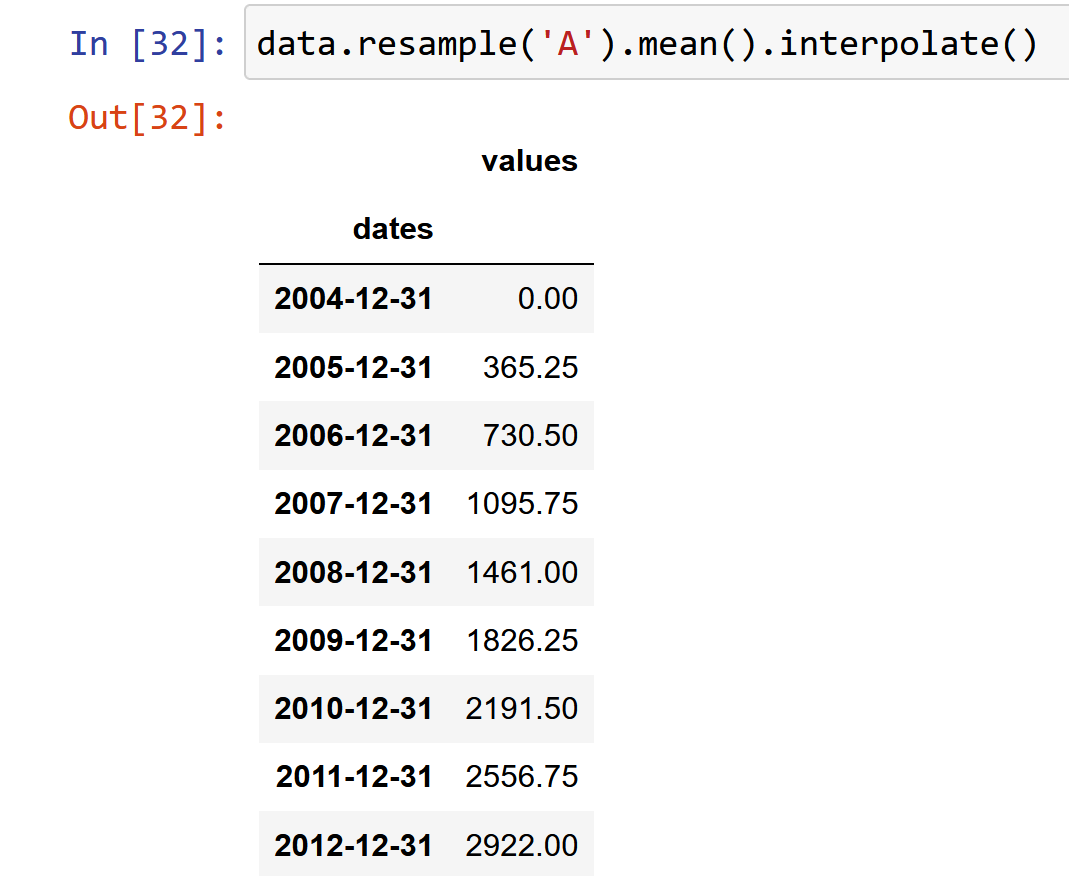
But what I want (and the problem is already the resampling and not the interpolation step) is
2004-12-31 365
2005-12-31 730
2006-12-31 1095
2007-12-31 1460
2008-12-31 1826
2009-12-31 2191
2010-12-31 2556
2011-12-31 2921
2012-12-31 3287
So I want an actual linear interpolation on the given data.
To make it even clearer I wrote a function which does the job. However, I'm still looking for a build in solution (my own function is bad coding because of a very ugly runtime):
def fillResampleCorrectly(data,resample):
for i in range(len(resample)):
currentDate=resample.index[i]
for j in range(len(data)):
if currentDate>=data.index[j]:
if j<len(data)-1:
continue
valueBefore=data[data.columns[0]].iloc[j-1]
valueAfter=data[data.columns[0]].iloc[j]
dateBefore=data.index[j-1]
dateAfter=data.index[j]
currentValue=valueBefore (valueAfter-valueBefore)*((currentDate-dateBefore)/(dateAfter-dateBefore))
resample[data.columns[0]].iloc[i]=currentValue
break
CodePudding user response:
I don't find a direct way for your exact output. The issue is the resampling between the 01-01 and 31-12 of the first year.
You can however mimick the result with:
out = data.resample('A', label='right').mean().interpolate(method='time') 365
Or:
s = data.resample('A', label='right').mean().interpolate(method='time')
out = s (s.index[0] - data.index[0]).days
Output:
values
dates
2004-12-31 365.0
2005-12-31 730.0
2006-12-31 1095.0
2007-12-31 1460.0
2008-12-31 1826.0
2009-12-31 2191.0
2010-12-31 2556.0
2011-12-31 2921.0
2012-12-31 3287.0
CodePudding user response:
What is “actual” interpolation? You are considering leap years, which makes this a non-linear relationship.
Generating a df that starts with the end of the year (and accounts for 2004 as a leap year):
data = pd.DataFrame({'dates': ['2004-12-31', '2008-12-31', '2012-12-31'], 'values': [
366 k * (1 4 * 365) for k in range(3)]})
data['dates'] = pd.to_datetime(data['dates'])
data = data.set_index('dates')
values
dates
2004-12-31 366
2008-12-31 1827
2012-12-31 3288
Resample and interpolation as before (data = data.resample('A').mean().interpolate()). By the way, A in resample is end of year, and AS is start of year.
If we look at the difference between each step (data - data.shift(1)), we get:
values
dates
2004-12-31 NaN
2005-12-31 365.25
2006-12-31 365.25
2007-12-31 365.25
2008-12-31 365.25
2009-12-31 365.25
2010-12-31 365.25
2011-12-31 365.25
2012-12-31 365.25
As we would expect from a linear interpolation.
The desired result can be achieved by applying np.floor to the results:
data.resample('A').mean().interpolate().apply(np.floor)
values
dates
2004-12-31 366.0
2005-12-31 731.0
2006-12-31 1096.0
2007-12-31 1461.0
2008-12-31 1827.0
2009-12-31 2192.0
2010-12-31 2557.0
2011-12-31 2922.0
2012-12-31 3288.0
And the difference data - data.shift(1):
values
dates
2004-12-31 NaN
2005-12-31 365.0
2006-12-31 365.0
2007-12-31 365.0
2008-12-31 366.0
2009-12-31 365.0
2010-12-31 365.0
2011-12-31 365.0
2012-12-31 366.0
A non-linear relationship caused by the leap year.
CodePudding user response:
I just came up with an idea and it works:
dailyData=data.asfreq('D').interpolate()
dailyData.groupby(dailyData.index.year).tail(1)
Only for the last year the wrong date is chosen, but that is completely fine for me. The important thing is that the days match to the values.