I have a table like below containing values for multiple IDs:
| ID | value | date |
|---|---|---|
| 1 | 20 | 2022-01-01 12:20 |
| 2 | 25 | 2022-01-04 18:20 |
| 1 | 10 | 2022-01-04 11:20 |
| 1 | 150 | 2022-01-06 16:20 |
| 2 | 200 | 2022-01-08 13:20 |
| 3 | 40 | 2022-01-04 21:20 |
| 1 | 75 | 2022-01-09 08:20 |
I would like to calculate week wise sum of values for all IDs:
The start date is given (for example, 01-01-2022).
Weeks are calculated based on range:
- every Saturday 00:00 to next Friday 23:59 (i.e. Week 1 is from 01-01-2022 00:00 to 07-01-2022 23:59)
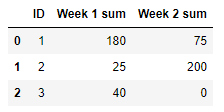
| ID | Week 1 sum | Week 2 sum | Week 3 sum | ... |
|---|---|---|---|---|
| 1 | 180 | 75 | -- | -- |
| 2 | 25 | 200 | -- | -- |
| 3 | 40 | -- | -- | -- |
CodePudding user response:
There's a pandas function (pd.Grouper) that allows you to specify a groupby instruction.1 In this case, that specification is to "resample" date by a weekly frequency that starts on Fridays.2 Since you also need to group by ID as well, add it to the grouper.
# convert to datetime
df['date'] = pd.to_datetime(df['date'])
# pivot the dataframe
df1 = (
df.groupby(['ID', pd.Grouper(key='date', freq='W-FRI')])['value'].sum()
.unstack(fill_value=0)
)
# rename columns
df1.columns = [f"Week {c} sum" for c in range(1, df1.shape[1] 1)]
df1 = df1.reset_index()
1 What you actually need is a pivot_table result but groupby unstack is equivalent to pivot_table and groupby unstack is more convenient here.
2 Because Jan 1, 2022 is a Saturday, you need to specify the anchor on Friday.
CodePudding user response:
You can compute a week column. In case you've data for same year, you can extract just week number, which is less likely in real-time scenarios. In case you've data from multiple years, it might be wise to derive a combination of Year & week number.
df['Year-Week'] = df['Date'].dt.strftime('%Y-%U')
In your case the dates 2022-01-01 & 2022-01-04 18:2 should be convert to 2022-01 as per the scenario you considered.
To calculate your pivot table, you can use the pandas pivot_table. Example code:
pd.pivot_table(df, values='value', index=['ID'], columns=['year_weeknumber'], aggfunc=np.sum)
CodePudding user response:
Let's define a formatting helper.
def fmt(row):
return f"{row.year}-{row.week:02d}" # We ignore row.day
Now it's easy.
>>> df = pd.DataFrame([dict(id=1, value=20, date="2022-01-01 12:20"),
dict(id=2, value=25, date="2022-01-04 18:20")])
>>> df['date'] = pd.to_datetime(df.date)
>>> df['iso'] = df.date.dt.isocalendar().apply(fmt, axis='columns')
>>> df
id value date iso
0 1 20 2022-01-01 12:20:00 2021-52
1 2 25 2022-01-04 18:20:00 2022-01
Just groupby the ISO week.