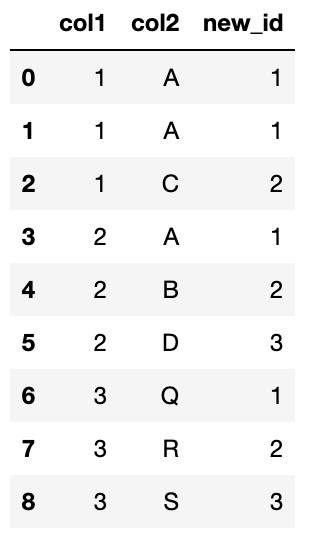
does anyone know how to group by two column in pandas i.e. col1 and ol2 shown in the screenshot and set a unique ID start from 1 if within the same col1 there are different col2? if the col1 is different, then the unique ID should start from 1 again.
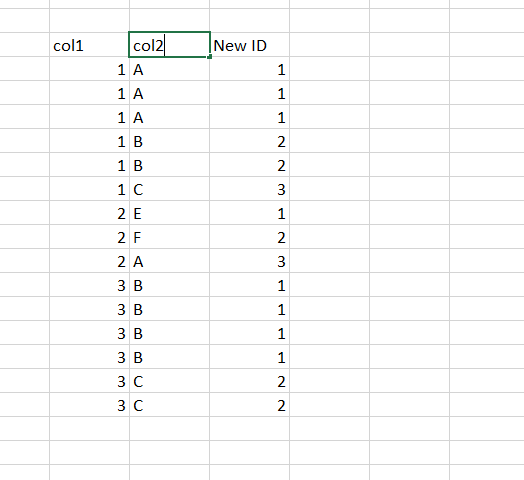
I couldnt find a way. my current solution does not meet my expectation as the unique id doesnt start from 1 if col1 is different.
df["NewID"] = df.groupby(['Col1','Col12'] ).ngroup().add(1).astype(str)
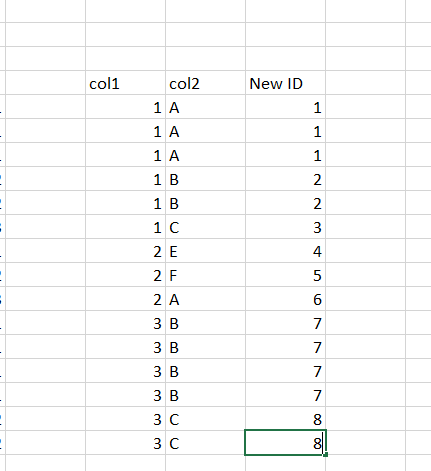
which gives me the following value
CodePudding user response:
You can use pd.factorize and groupby:
new_id = lambda x: pd.factorize(x)[0] 1
df['New ID'] = df.groupby('col1')['col2'].transform(new_id)
print(df)
# Output
col1 col2 New ID
0 1 A 1
1 1 A 1
2 1 A 1
3 1 B 2
4 1 B 2
5 1 C 3
6 2 E 1
7 2 F 2
8 2 A 3
9 3 B 1
10 3 B 1
11 3 B 1
12 3 B 1
13 3 C 2
14 3 C 2
Or:
new_id = lambda x: x.ne(x.shift()).cumsum()
df['New ID'] = df.groupby('col1')['col2'].transform(new_id)
CodePudding user response:
You can also groupby within each group
import pandas as pd
df = pd.DataFrame({
'col1':[1,1,1,2,2,2,3,3,3],
'col2':['A','A','C','A','B','D','Q','R','S'],
})
#groupby twice to restart the group numbering
df['new_id'] = df.groupby('col1').apply(lambda g: g.groupby('col2').ngroup()).add(1).values
Output: