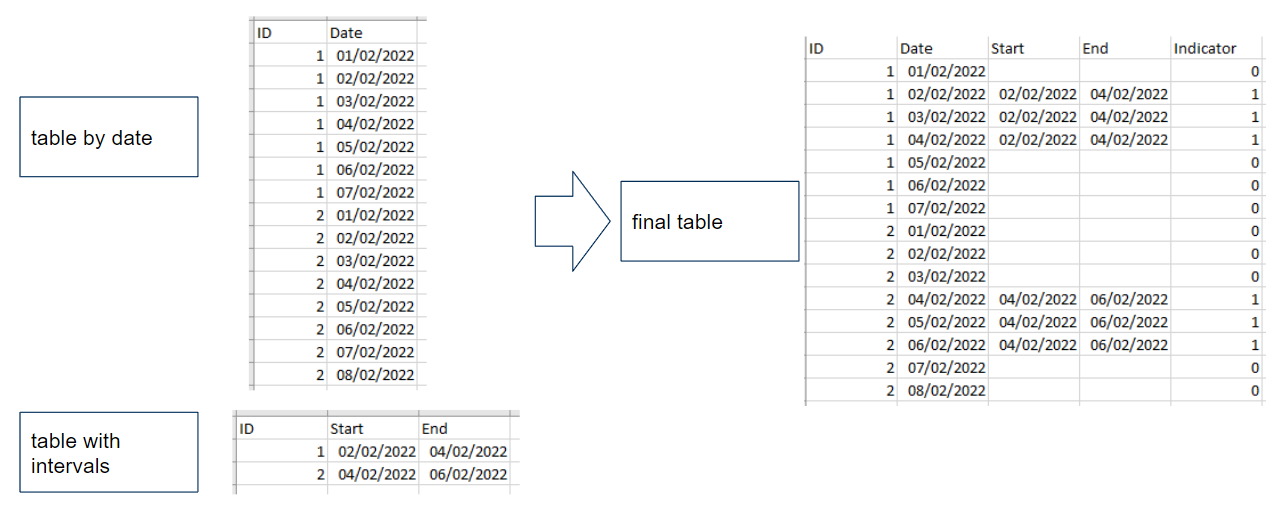
The question can be summarized in this image
- I have a table (df1) with ID column, and dates
- Another table (df2) with date intervals
- I want a final table to indicate if each date is in one of the intervals.
print(df1)
ID Date
0 1 2022-02-01
1 1 2022-02-02
2 1 2022-02-03
3 1 2022-02-04
4 1 2022-02-05
5 1 2022-02-06
6 1 2022-02-07
7 2 2022-02-01
8 2 2022-02-02
9 2 2022-02-03
10 2 2022-02-04
11 2 2022-02-05
12 2 2022-02-06
13 2 2022-02-07
14 2 2022-02-08
Here is :
print(df2)
ID Start End
0 1 2022-02-02 2022-02-04
1 2 2022-02-04 2022-02-06
I tried one solution posted here,
idx = pd.IntervalIndex.from_arrays(df_2['Start'], df_2['End'], closed='both')
df_2.index=idx
df_1['event']=df_2.loc[df_1.Date,'event'].values
But I got an error
KeyError: "[Timestamp('2022-02-01 00:00:00'), Timestamp('2022-02-07 00:00:00'), Timestamp('2022-02-08 00:00:00')] not in index"
Since not all the dates are in the index, this solution does not work.
So I would like to know how to solve this problem.
EDIT: there can be multiple intervals for each ID in df2, for example
data_df2 = StringIO("""
ID;Start;End
1;2022-02-02;2022-02-04
1;2022-02-06;2022-02-07
2;2022-02-04;2022-02-06
"""
)
CodePudding user response:
This is a job for a left join using merge.
First, you add the relevant start and end dates from df2 to each date in df1. Second, you construct the indicator variable where you assign the value of 1 if the date is within the interval and 0 otherwise.
from io import StringIO
import pandas as pd
import numpy as np
# setup df1
data = StringIO("""
ID;Date
1;2022-02-01
1;2022-02-02
1;2022-02-03
1;2022-02-04
1;2022-02-05
1;2022-02-06
1;2022-02-07
2;2022-02-01
2;2022-02-02
2;2022-02-03
2;2022-02-04
2;2022-02-05
2;2022-02-06
2;2022-02-07
2;2022-02-08
"""
)
df1 = pd.read_csv(data, sep=";")
df1['Date'] = pd.to_datetime(df1['Date'])
# setup df2
data = StringIO("""
ID;Start;End
1;2022-02-02;2022-02-04
2;2022-02-04;2022-02-06
"""
)
df2 = pd.read_csv(data, sep=";")
df2['Start'] = pd.to_datetime(df2['Start'])
df2['End'] = pd.to_datetime(df2['End'])
# merge interval from df2 to dates in df1
df3 = df1.merge(
df2,
on='ID',
how='left'
)
# create indicator variable
df3['indicator'] = np.where(
(df3['Date']>=df3['Start'])&(df3['Date']<=df3['End']),
1,
0
)
To match your desired result, you can now get rid of the start and end dates for rows with a date outside of the interval
df3.loc[df3['indicator']==0,['Start','End']] = pd.NaT
The result:
ID Date Start End indicator
0 1 2022-02-01 NaT NaT 0
1 1 2022-02-02 2022-02-02 2022-02-04 1
2 1 2022-02-03 2022-02-02 2022-02-04 1
3 1 2022-02-04 2022-02-02 2022-02-04 1
4 1 2022-02-05 NaT NaT 0
5 1 2022-02-06 NaT NaT 0
6 1 2022-02-07 NaT NaT 0
7 2 2022-02-01 NaT NaT 0
8 2 2022-02-02 NaT NaT 0
9 2 2022-02-03 NaT NaT 0
10 2 2022-02-04 2022-02-04 2022-02-06 1
11 2 2022-02-05 2022-02-04 2022-02-06 1
12 2 2022-02-06 2022-02-04 2022-02-06 1
13 2 2022-02-07 NaT NaT 0
14 2 2022-02-08 NaT NaT 0
Response to edited question
Because you need to be able to compare each date with all intervals, conditional on the ID, I believe this is the approach to take. However, you may choose to reduce the resulting dataframe.
You did not specify what this should look like. I can imagine the following would suit your situation: (1) If there is at least one interval which includes the date, then keep all of them. (2) If there is no such interval, then only keep one row with missing dates for the interval and a value of 0 for the indicator.
If so, then after you apply the above code to your (new) raw data, execute the following
df3.groupby(['ID','Date'])[['Start','End','indicator']].apply(lambda x: x[x['indicator']==1] if x['indicator'].sum()>0 else pd.DataFrame([[pd.NaT,pd.NaT,0]], columns=x.columns))
Resulting dataframe:
Start End indicator
ID Date
1 2022-02-01 0 NaT NaT 0
2022-02-02 2 2022-02-02 2022-02-04 1
2022-02-03 4 2022-02-02 2022-02-04 1
2022-02-04 6 2022-02-02 2022-02-04 1
2022-02-05 0 NaT NaT 0
2022-02-06 11 2022-02-06 2022-02-07 1
2022-02-07 13 2022-02-06 2022-02-07 1
2 2022-02-01 0 NaT NaT 0
2022-02-02 0 NaT NaT 0
2022-02-03 0 NaT NaT 0
2022-02-04 17 2022-02-04 2022-02-06 1
2022-02-05 18 2022-02-04 2022-02-06 1
2022-02-06 19 2022-02-04 2022-02-06 1
2022-02-07 0 NaT NaT 0
2022-02-08 0 NaT NaT 0
If you have memory constraints, you can execute the code sequentially in chunks of df1, then append the result to an initialized dataframe or list.