The model introduced
Text recognition (OCR) model based on the network architecture of network + two-way LSTM, one of the basic network selection is VGG16, character recognition is case sensitive, 26 letters + 10 Numbers a total of 36 characters, its network structure similar to the following:
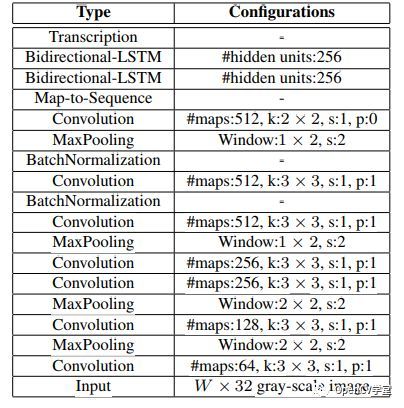
Model input structure is:
[BxCxHxW]=1 x1x32x120
The B said batch, said channel C, H, W said width
Model output is:
[WxBxL]=30 x1x37
The B said batch, W represents the output sequence length, L said all their score 37 characters, with a 37 is #
Output part analysis based on CTC greedy decoding way,
code
Load model
# loading IRThe log. The info (" Reading IR...
")Net=IENetwork (model=model_xml, weights=model_bin)
Text_net=IENetwork (model=text_xml, weights=text_bin) Scene text detection
# image=cv2. Imread (" D:/images/openvino_ocr. PNG ");
Image=cv2. Imread (" D:/images/cover_01. JPG ");
Cv2. Imshow (" image ", image)
Inf_start=time. Time ()
In_frame=cv2. Resize (image, (w, h))
In_frame=in_frame. Transpose ((2, 0, 1)) # Change data layout from HWC to CHW
In_frame=in_frame. Reshape ((n, c, h, w))
Exec_net. Infer (inputs)={input_blob: in_frame} ROI interception and character recognition
x, y, width, height=cv2. BoundingRect (contours [c])
ROI=image [y - 5: y + height + 10, x - 5: width x + + 10, :)
Gray=cv2. CvtColor (ROI, cv2 COLOR_BGR2GRAY)
Text_roi=cv2. Resize (gray, (tw, th))
Text_roi=np. Expand_dims (text_roi, 2)
Text_roi=text_roi. Transpose ((2, 0, 1))
Text_roi=text_roi. Reshape ((tn, tc, th, tw))
Text_exec_net. Infer (inputs={input_blob: text_roi})
Text_out=text_exec_net. Requests [0]. Outputs [text_out_blob]
CTC analytical results
# parse the output text
Ocrstr=""
Prev_pad=False;
For I in range (text_out shape [0]) :
CTC=text_out [I]
CTC=np. Squeeze (CTC, 0)
The index, prob=ctc_soft_max (CTC)
If alphabet [index]=='#' :
Prev_pad=True
The else:
If len (ocrstr)==0 or prev_pad or (len (ocrstr) & gt; 0 and alphabet [index]!=ocrstr [1]) :
Prev_pad=False
Ocrstr +=alphabet [index]
The output text detection and recognition results
# show identification resultsPrint (" result: % s "% ocrstr)
Cv2. DrawContours (image, [box], 0, (0, 255, 0), (2)
Cv2. PutText (image, ocrstr, (x, y), cv2. FONT_HERSHEY_COMPLEX, 0.75, (255, 0, 0), (1)
Finally on the demo code
def demo () :
# loading MKLDNN - CPU Target
The basicConfig (format="(levelname) [% s] % s" (the message), level=the INFO, stream=sys. Stdout)
The plugin=IEPlugin (device="CPU", plugin_dirs=plugin_dir)
The plugin. Add_cpu_extension (cpu_extension)
# loading IR
The log. The info (" Reading IR...
")Net=IENetwork (model=model_xml, weights=model_bin)
Text_net=IENetwork (model=text_xml, weights=text_bin)
If the plugin. The device=="CPU" :
Supported_layers=plugin. Get_supported_layers (net)
Not_supported_layers=[l for l in.net. The layers. The keys () if not in supported_layers] l
If len (not_supported_layers)!=0:
The log. The error (" Following the layers are not supported by the plugin for specified device: {} \ n {} ".
Format (plugin. The device, ', '. Join (not_supported_layers)))
The log. The error (" both Please try to specify the CPU extensions library path in the demo 's command line parameters using the -l
""The or - cpu_extension command line argument")
Sys. Exit (1)
# for input and output layer
Input_blob=next (iter (net. Inputs))
Outputs=iter (net. Outputs)
# take multiple output layer name
Out_blob=next (outputs)
Second_blob=next (outputs)
The info (" Loading the IR to the plugin...
")Print (" pixel output: % s, link the output: % s \ n "% (out_blob second_blob))
Text_input_blob=next (iter (text_net. Inputs))
Text_out_blob=next (iter (text_net outputs))
Print (" text_out_blob: % s "% text_out_blob)
# to create an executable network
Exec_net=plugin. The load (network=net)
Text_exec_net=plugin. The load (network=text_net)
# Read and pre - process the input image
N, c, h, w=net. Inputs [input_blob]. Shape
Tn, tc, th, tw=text_net inputs [text_input_blob]. Shape
Del.net
Del text_net
The info (" Starting inference in async mode...
")The info (" To switch between the sync and async modes, press Tab button ")
The info (" To stop the demo execution press Esc button ")
Image=cv2. Imread (" D:/images/openvino_ocr. PNG ");
# image=cv2. Imread (" D:/images/cover_01. JPG ");
Cv2. Imshow (" image ", image)
Inf_start=time. Time ()
In_frame=cv2. Resize (image, (w, h))
In_frame=in_frame. Transpose ((2, 0, 1)) # Change data layout from HWC to CHW
In_frame=in_frame. Reshape ((n, c, h, w))
Exec_net. Infer (inputs={input_blob: in_frame})
Inf_end=time. Time ()
Det_time=inf_end - inf_start
# get output
Res1=exec_net. Requests [0]. Outputs [out_blob]
Res2=exec_net. Requests [0]. Outputs [second_blob]
# dimension reduction
nullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnull