The goal is to read the 1-5yr GIC rates for Guaranteed Investment Certificate - Long-Term and Compound Interest under the Non-Cashable GICs tab.
Selector Gadget tells me that the css identifier is #container-9565195e5e .cmp-chart__chart span. Using rvest:
page <- read_html('https://www.td.com/ca/en/personal-banking/products/saving-investing/gic-rates-canada/')
page %>%
html_nodes("#container-9565195e5e .cmp-chart__chart span")
# {xml_nodeset (5)}
# [1] <span data-source="tdct-gic" data-view="single" data-filter-item="productId:315|minimumDepositAmt:0.01|minimumTermYearCnt:1" data-value="postedRate"></span>
# [2] <span data-source="tdct-gic" data-view="single" data-filter-item="productId:315|minimumDepositAmt:0.01|minimumTermYearCnt:2" data-value="postedRate"></span>
# [3] <span data-source="tdct-gic" data-view="single" data-filter-item="productId:315|minimumDepositAmt:0.01|minimumTermYearCnt:3" data-value="postedRate"></span>
# [4] <span data-source="tdct-gic" data-view="single" data-filter-item="productId:315|minimumDepositAmt:0.01|minimumTermYearCnt:4" data-value="postedRate"></span>
# [5] <span data-source="tdct-gic" data-view="single" data-filter-item="productId:315|minimumDepositAmt:0.01|minimumTermYearCnt:5" data-value="postedRate"></span>}
rvest can't read the actual rates because of the use of JavaScript on the site.
Turning to RSelenium using the same css selector results in an error:
remDr$navigate("https://www.td.com/ca/en/personal-banking/products/saving-investing/gic-rates-canada/")
webElem <- remDr$findElement(using = "css", "#container-9565195e5e .cmp-chart__chart span")
# Selenium message:Unable to locate element: {"method":"css selector","selector":"#container-9565195e5e .cmp-chart__chart span"}
# For documentation on this error, please visit: http://seleniumhq.org/exceptions/no_such_element.html
# Build info: version: '2.53.1', revision: 'a36b8b1', time: '2016-06-30 17:37:03'
# System info: host: 'ef4080d2cb73', ip: '172.17.0.2', os.name: 'Linux', os.arch: 'amd64', os.version: '5.4.0-135-generic', java.version: '1.8.0_91'
# Driver info: driver.version: unknown
#
# Error: Summary: NoSuchElement
# Detail: An element could not be located on the page using the given search parameters.
# class: org.openqa.selenium.NoSuchElementException
# Further Details: run errorDetails method
So how do I use RSelenium to read the 1-5yr rates for Guaranteed Investment Certificate - Long-Term and Compound Interest for Non-registered and Registered (TFSA, RSP, RIF, RESP)
CodePudding user response:
Replaced RSelenium with Chromote (which is on its way to rvest: r4ds, gh). The selector in question seems to refer to another table, Long-Term and Simple Interest. While values are currently the same, still switched to the one mentioned in question.
library(chromote)
library(rvest)
b <- ChromoteSession$new()
# Display the current session in the Chromote browser:
# b$view()
b$Page$navigate("https://www.td.com/ca/en/personal-banking/products/saving-investing/gic-rates-canada/")
b$Page$loadEventFired()
# Non-Cashable GICs >> Guaranteed Investment Certificate - Long-Term and Compound Interest
b$Runtime$evaluate("document.querySelector('#container-8a263227af table').outerHTML")$result$value %>%
minimal_html() %>%
html_element("table") %>%
html_table()
#> # A tibble: 5 × 2
#> Term `Non-registered and Registered (TFSA, RSP, RIF, RESP)`
#> <chr> <chr>
#> 1 1 year 4.65%
#> 2 2 years 4.35%
#> 3 3 years 3.75%
#> 4 4 years 4%
#> 5 5 years 4.05%
### Few alternatives
# evalute js in runtime:
sapply(1:5, \(x) b$Runtime$evaluate(paste0("document.querySelector('[data-filter-item=\"productId:703|minimumDepositAmt:0.01|minimumTermYearCnt:",x,"\"]').innerText"))$result$value)
#> [1] "4.65" "4.35" "3.75" "4" "4.05"
doc <- b$DOM$getDocument()
# elements where "data-filter-item" attribute starts with "productId:703|minimumDepositAmt:0.01|minimumTermYearCnt:"
nodeids <- b$DOM$querySelectorAll(doc$root$nodeId, '[data-filter-item^="productId:703|minimumDepositAmt:0.01|minimumTermYearCnt:"]')
sapply(nodeids$nodeIds, \(x) b$DOM$getOuterHTML(x) %>% minimal_html() %>% html_text())
#> [1] "4.65" "4.35" "3.75" "4" "4.05"
# close session
b$close()
#> [1] TRUE
Created on 2023-01-21 with reprex v2.0.2
CodePudding user response:
The page does an initial POST request that gets all the data (let's call it master) for all the options. It then uses the various data-filter-item attribute values associated with the table cells e.g. data-filter-item="productId:703|minimumDepositAmt:0.01|minimumTermYearCnt:1" to filter the master data initially returned to the items specific to the table and updates the table accordingly.
You can replicate this post request, create a dataframe of all values, then extract the required filters
> filters
[1] "productId:703|minimumDepositAmt:0.01|minimumTermYearCnt:1" "productId:703|minimumDepositAmt:0.01|minimumTermYearCnt:2"
[3] "productId:703|minimumDepositAmt:0.01|minimumTermYearCnt:3" "productId:703|minimumDepositAmt:0.01|minimumTermYearCnt:4"
[5] "productId:703|minimumDepositAmt:0.01|minimumTermYearCnt:5"
and turn into a dataframe, then subset the master table by the smaller dataframe (as column names will be matched upon if set in the master using the key values from the key:value response.)
Finally, update the table, when extracted from request response for initial webpage, by updating the relevant column with the rate % from the filtered master dataframe.
The html from the initial webpage is invalid so the css path is not as straightforward as I would like, but the selector list I went with was designed with hopefully a longer shelf-life in terms of remaining valid for longer than a more brittle path might.
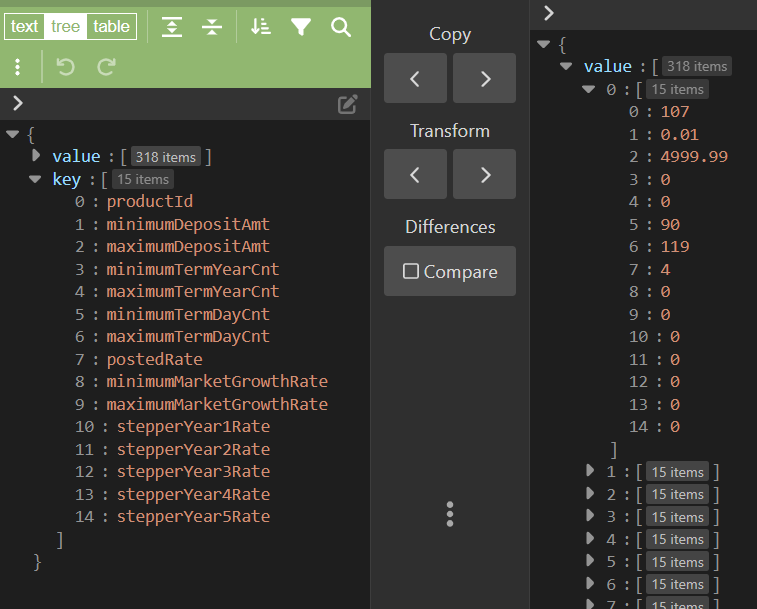
One other thing to show might be the response from the POST request which has the following key:value format where I use the key column to generate headers for my filtering instructions dataframe, and the values get turned into the master dataframe of all possible rates (and other dynamic page info)
Credit:
I took the approach used by @akrun in their answer here, whereby read.dcf is used to map out a set of rows with potentially repeated/new headers into a single dataframe with all headers present and NA entered if a particular entry is not present in a given processed row.
This allowed me to turn this list of split filtering instructions:
> lapply(filters, str_split, "\\|") %>% unlist(recursive = F)
[[1]]
[1] "productId:703" "minimumDepositAmt:0.01" "minimumTermYearCnt:1"
[[2]]
[1] "productId:703" "minimumDepositAmt:0.01" "minimumTermYearCnt:2"
[[3]]
[1] "productId:703" "minimumDepositAmt:0.01" "minimumTermYearCnt:3"
[[4]]
[1] "productId:703" "minimumDepositAmt:0.01" "minimumTermYearCnt:4"
[[5]]
[1] "productId:703" "minimumDepositAmt:0.01" "minimumTermYearCnt:5"
into this:
> data_df
productId minimumDepositAmt minimumTermYearCnt
1 703 0.01 1
2 703 0.01 2
3 703 0.01 3
4 703 0.01 4
5 703 0.01 5
i.e. the set of filtering instructions for the master dataframe as a dataframe
The master dataframe looking as follows:
> df %>% head()
productId minimumDepositAmt maximumDepositAmt minimumTermYearCnt maximumTermYearCnt minimumTermDayCnt maximumTermDayCnt postedRate
1 107 0.01 4999.99 0 0 90 119 4
2 107 5000 9999.99 0 0 90 119 4
3 107 10000 24999.99 0 0 90 119 4
4 107 25000 49999.99 0 0 90 119 4
5 107 50000 99999.99 0 0 90 119 4
6 107 100000 249999.99 0 0 90 119 4
minimumMarketGrowthRate maximumMarketGrowthRate stepperYear1Rate stepperYear2Rate stepperYear3Rate stepperYear4Rate stepperYear5Rate
1 0 0 0 0 0 0 0
2 0 0 0 0 0 0 0
3 0 0 0 0 0 0 0
4 0 0 0 0 0 0 0
5 0 0 0 0 0 0 0
6 0 0 0 0 0 0 0
The subset master dataframe:
> filtered_df
productId minimumDepositAmt minimumTermYearCnt maximumDepositAmt maximumTermYearCnt minimumTermDayCnt maximumTermDayCnt postedRate
1 703 0.01 1 4999.99 1 0 364 4.65
2 703 0.01 2 4999.99 2 0 364 4.35
3 703 0.01 3 4999.99 3 0 364 3.75
4 703 0.01 4 4999.99 4 0 364 4
5 703 0.01 5 4999.99 5 0 364 4.05
minimumMarketGrowthRate maximumMarketGrowthRate stepperYear1Rate stepperYear2Rate stepperYear3Rate stepperYear4Rate stepperYear5Rate
1 0 0 0 0 0 0 0
2 0 0 0 0 0 0 0
3 0 0 0 0 0 0 0
4 0 0 0 0 0 0 0
5 0 0 0 0 0 0 0
The extracted table, from initial page, before update:
> table
# A tibble: 5 × 2
Term `Non-registered and Registered (TFSA, RSP, RIF, RESP)`
<chr> <chr>
1 1 year %
2 2 years %
3 3 years %
4 4 years %
5 5 years %
And the table after update using master (df - data from POST request to get rates info):
> print(table)
# A tibble: 5 × 2
Term `Non-registered and Registered (TFSA, RSP, RIF, RESP)`
<chr> <chr>
1 1 year 4.65%
2 2 years 4.35%
3 3 years 3.75%
4 4 years 4%
5 5 years 4.05%
r:
library(rvest)
library(tidyverse)
library(httr2)
page <- read_html("https://www.td.com/ca/en/personal-banking/personal-investing/products/gic/gic-rates-canada")
table_node <- page %>%
html_element('div.container:contains("Guaranteed Investment Certificate - Long-Term") .text:contains("Compound") ~ div table')
filters <- table_node %>%
html_elements("[data-filter-item]") %>%
html_attr("data-filter-item")
res <- request("https://www.td.com/ca/en/personal-banking/getRates/") %>%
req_headers(
"user-agent" = "Mozilla/4.0", "content-type" = "application/json",
"x-kl-ajax-request" = "Ajax_Request"
) %>%
req_body_json(list("errorText" = "Unable to get the rate", "ratesType" = "gic")) %>%
req_perform() %>%
resp_body_string()
data <- jsonlite::parse_json(res, simplifyVector = T)
df <- set_names(data$value %>% as.data.frame(), data$key)
data_df <- map_dfr(lapply(filters, str_split, "\\|") %>% unlist(recursive = F), ~ {
new <-
if (length(new) > 0) {
as.data.frame(read.dcf(textConnection(.x)))
} else {
NULL
}
})
filtered_df <- inner_join(data_df, df)
table <- table_node %>% html_table()
table[2] <- str_c(filtered_df$postedRate, table[[2]])
print(table)