I have a data set resembling the following:
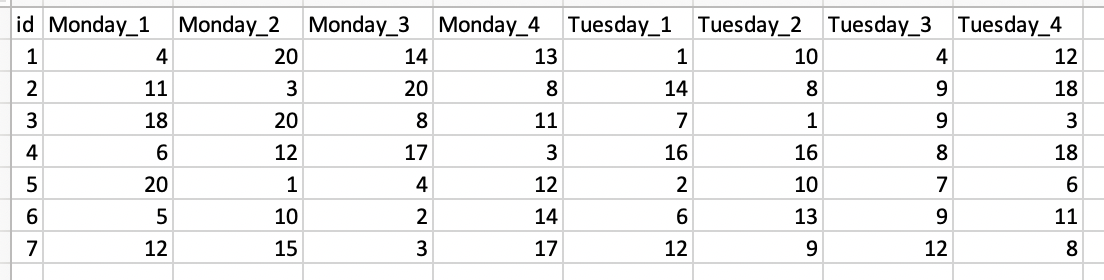
I want to subtract the value of all Tuesdays from corresponding values of Mondays. So the resulting first column would be Monday_1 - Tuesday_1, second resulting column would be Monday_2 - Tuesday_2, and so on.
Here is what the resulting data frame would look like.
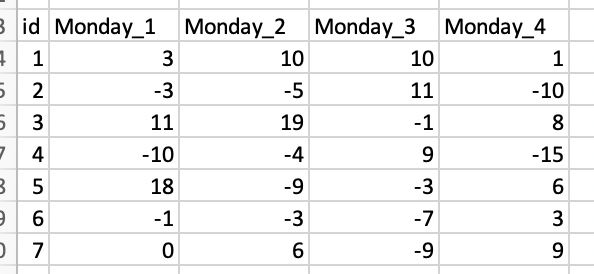
I would like to keep the names of the Monday columns the same and select out the Tuesday cols. My real data set is much wider than this so not having to manually subtract is much easier. Ideally I want a dplyr solution.
Data:
df <- structure(list(id = 1:7, Monday_1 = c(4L, 11L, 18L, 6L, 20L,
5L, 12L), Monday_2 = c(20L, 3L, 20L, 12L, 1L, 10L, 15L), Monday_3 = c(14L,
20L, 8L, 17L, 4L, 2L, 3L), Monday_4 = c(13L, 8L, 11L, 3L, 12L,
14L, 17L), Tuesday_1 = c(1L, 14L, 7L, 16L, 2L, 6L, 12L), Tuesday_2 = c(10L,
8L, 1L, 16L, 10L, 13L, 9L), Tuesday_3 = c(4L, 9L, 9L, 8L, 7L,
9L, 12L), Tuesday_4 = c(12L, 18L, 3L, 18L, 6L, 11L, 8L)), class = "data.frame", row.names = c(NA,
-7L))
CodePudding user response:
using across gives you this easily:
df |>
mutate(across(.cols = starts_with("Monday")) - across(.cols = starts_with("Tuesday"))) |>
select(id, starts_with("Monday"))
#> id Monday_1 Monday_2 Monday_3 Monday_4
#> 1 1 3 10 10 1
#> 2 2 -3 -5 11 -10
#> 3 3 11 19 -1 8
#> 4 4 -10 -4 9 -15
#> 5 5 18 -9 -3 6
#> 6 6 -1 -3 -7 3
#> 7 7 0 6 -9 9
CodePudding user response:
Using dplyrs summarize
library(dplyr)
df %>%
summarize(id, across(starts_with("Monday")) - across(starts_with("Tuesday")))
id Monday_1 Monday_2 Monday_3 Monday_4
1 1 3 10 10 1
2 2 -3 -5 11 -10
3 3 11 19 -1 8
4 4 -10 -4 9 -15
5 5 18 -9 -3 6
6 6 -1 -3 -7 3
7 7 0 6 -9 9