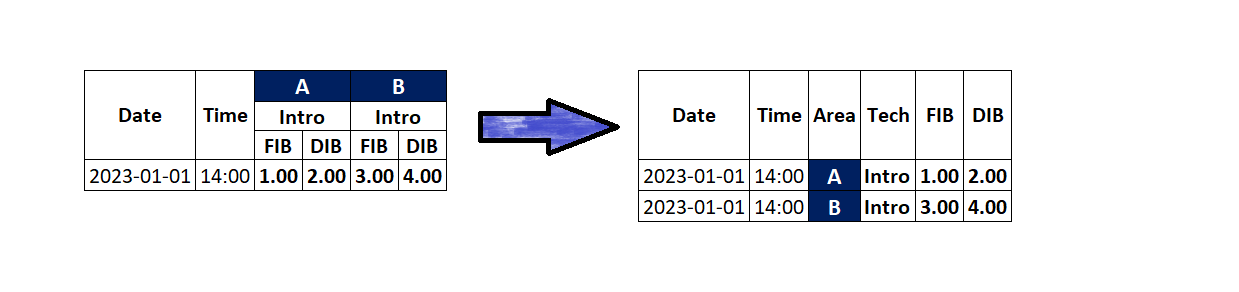
I have tried melt, unstack and stack pandas functions but cannot understand how to implement them.
dataframe trasnformation and reformating:
CodePudding user response:
I suppose that the required transformation just can't be in a straightforward way done using Pandas functions because the source data structure does not fit well into the concept of a Pandas DataFrame and in addition to this it also does not contain the information about the required column names and columns the target DataFrame is expected to have along with the number of necessary duplicates of rows.
See the Python code illustrating the problem by providing dictionaries for the data tables:
import pandas as pd
pd_json_dict_src = {
'Date':'2023-01-01',
'Time':'14:00',
'A':{
'Intro':[
{'FIB':'1.00'},
{'DIB':'2.00'} ] },
'B':{
'Intro':[
{'FIB':'3.00'},
{'DIB':'4.00'} ] }
}
df_src = pd.DataFrame.from_dict(pd_json_dict_src)
print(df_src)
# -----------------------------------------------
pd_json_dict_tgt = {
'Date':['2023-01-01','2023-01-01'],
'Time':['14:00','14:00'],
'Area':['A','B'],
'Tech':['Intro','Intro'],
'FIB' :['1.00','3.00'],
'DIB' :['2.00','4.00']
}
df_tgt = pd.DataFrame.from_dict(pd_json_dict_tgt)
print(df_tgt)
prints
Date ... B
Intro 2023-01-01 ... [{'FIB': '3.00'}, {'DIB': '4.00'}]
[1 rows x 4 columns]
Date Time Area Tech FIB DIB
0 2023-01-01 14:00 A Intro 1.00 2.00
1 2023-01-01 14:00 B Intro 3.00 4.00
I don't also see any easy to code automated way able to transform the by the dictionary defined source data structure into the data structure of the target dictionary.
In other words it seems that there is no straightforward and easy to code general way of flattening column-wise deep nested data structures especially when choosing Python Pandas as a tool for such flattening. At least as long as there is no other answer here proving me and this statement wrong.
CodePudding user response:
Create the dataframe:
df = pd.DataFrame(data=[["2023-01-01","14:00",1.0,2.0,3.0,4.0]])
0 1 2 3 4 5
0 2023-01-01 14:00 1.00 2.00 3.00 4.00
Set the index columns:
df = df.set_index([0,1]).rename_axis(["Date", "Time"])
2 3 4 5
Date Time
2023-01-01 14:00 1.00 2.00 3.00 4.00
Create the multi-level columns:
df.columns = pd.MultiIndex.from_tuples([("A", "Intro", "FIB"), ("A", "Intro", "DIB"), ("B", "Intro", "FIB"), ("B", "Intro", "DIB")], names=["Area", "Tech", ""])
Area A B
Tech Intro Intro
FIB DIB FIB DIB
Date Time
2023-01-01 14:00 1.00 2.00 3.00 4.00
Use stack() on levels "Area" and "Tech":
df = df.stack(["Area","Tech"])
DIB FIB
Date Time Area Tech
2023-01-01 14:00 A Intro 2.00 1.00
B Intro 4.00 3.00
Reset index to create columns "Date" and "Time" and repeat their values:
df = df.reset_index()
Date Time Area Tech DIB FIB
0 2023-01-01 14:00 A Intro 2.00 1.00
1 2023-01-01 14:00 B Intro 4.00 3.00