I'm trying to figure out, for each duplicate group in column A, if that group has data in column b. If so, mark column c as a 1 for that group of duplicates. How can I do this please?
Sample data:
CREATE TABLE #t10
(
docid VARCHAR (20) NULL
, leaveDate DATE NULL
)
INSERT INTO #t10(
docid
, leaveDate
)
VALUES
('abcde123' , '20230101')
,('abcde123' , null)
,('defg123' , null)
,('defg123' , null)
,('hijk123' , null)
,('hijk123' , null)
SELECT docid
, leaveDate
FROM #t10
Desired Results:
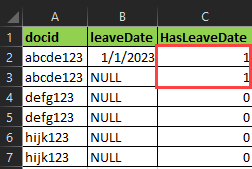
CodePudding user response:
As I mentioned in the comments, a windowed COUNT and a CASE expression is likely all you need here:
CASE COUNT(LeaveDate) OVER (PARTITION BY DocID) WHEN 0 THEN 0 ELSE 1 END