Input JSON
{
"tables": {
"Cloc": {
"MINT": {
"CANDY": {
"Mob": [{
"loc": "AA",
"loc2": ["AAA"]
},
{
"loc": "AA",
"loc2": ["AAA"]
}
]
}
}
},
"T1": {
"MINT": {
"T2": {
"T3": [{
"loc": "AAA",
"loc2": ["AAA"]
}]
}
}
}
}
}
Expected Output
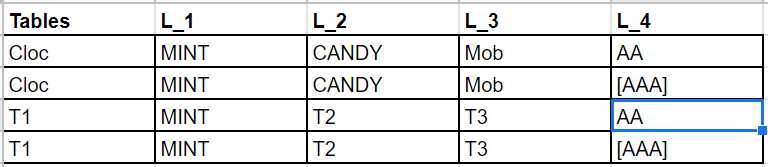
=========================================
I have tried processing this nested JSON using pd.json_normalize()
data = pd.DataFrame(nested_json['tables']['Cloc']['MINT']['CANDY']['Mob'])
I have no clue how to proceed, any help or guidance is highly appreciated.
Many Thanks!!
CodePudding user response:
Assuming only the final level consists of a list of dictionaries, you could simply compute the rows. We could do this recursively, so that it works for any number of nesting levels.
rows = []
def find_rows(x, current_row):
if isinstance(x, dict):
for k,v in x.items():
find_rows(v, current_row [k])
else: # we are at the final level, where we have a list of dictionaries
for locs_map in x:
for v in locs_map.values():
rows.append(current_row [v])
find_rows(d['tables'], [])
# Now I'm assuming you have only the number of levels as in your example
data = pd.DataFrame.from_records(rows, columns= ['Tables', 'L_1', 'L_2', 'L_3', 'L_4'])
data = data.loc[data.astype(str).drop_duplicates().index]