I'm new to using Selenium and I have trouble with scraping data between two h3 tags.
Here's a part of the HTML code that I'm trying to scrape, the web site is 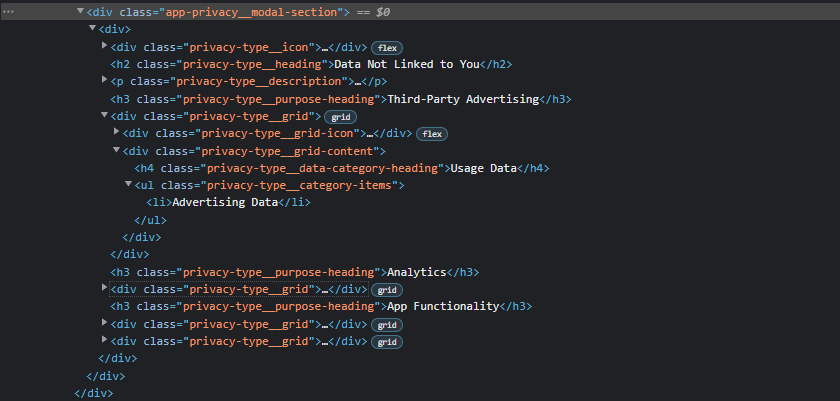
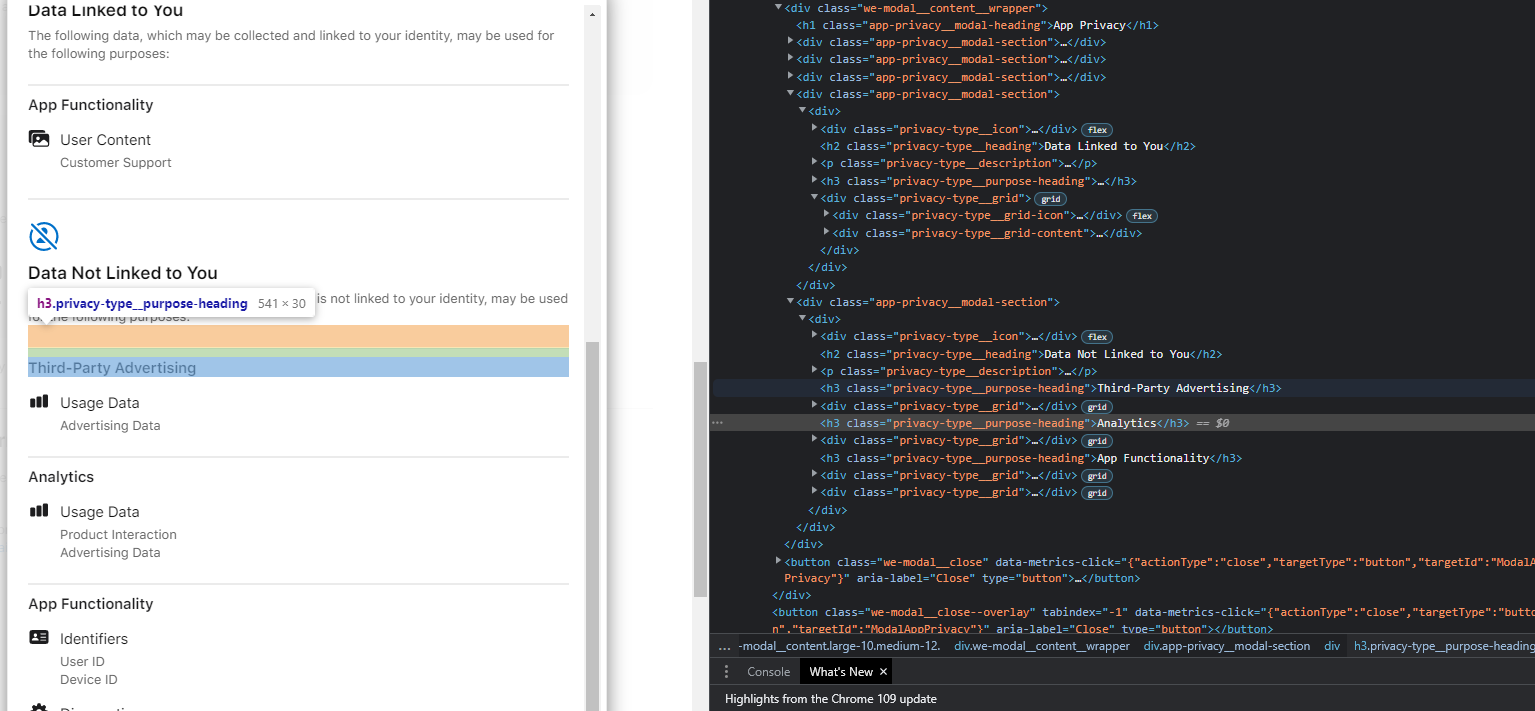
App Functionality
Customer Support
Third-Party Advertising
Advertising Data
Analytics
Product Interaction
Advertising Data
App Functionality
User ID
Device ID
Crash Data
Performance Data
Other Diagnostic Data
Above is what I wanted to grab, but I got as below:
App Functionality
Customer Support
-----------------------
Third-Party Advertising
Advertising Data
Product Interaction
Advertising Data
User ID
Device ID
Crash Data
Performance Data
Other Diagnostic Data
-----------------------
Analytics
Product Interaction
Advertising Data
User ID
Device ID
Crash Data
Performance Data
Other Diagnostic Data
-----------------------
App Functionality
User ID
Device ID
Crash Data
Performance Data
Other Diagnostic Data
-----------------------
It seems the results contain all li elements after next h3 tags, and my code is:
h3_tags = WebDriverWait(driver, 15).until(
EC.presence_of_all_elements_located((By.XPATH, "//h3[@class='privacy-type__purpose-heading']"))
)
for i in range(len(h3_tags)):
li_tags = h3_tags[i].find_elements(By.XPATH, "./following-sibling::div[@class='privacy-type__grid']/descendant::li")
print(h3_tags[i].text)
for li in li_tags:
print(li.text)
print('-----------------------')
Is there any way to only keep the li-element between two h3 tags?
Thanks!
CodePudding user response:
It seems the results contain all li elements after next h3 tags
This happens because following-sibling selects all the siblings following a given node. For example if h3_tags[i] is "Third-Party Advertising", then the xpath
./following-sibling::div[@class='privacy-type__grid']
selects all the four div elements following h3, instead of only the first one.
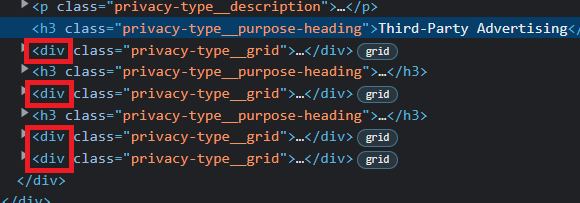
What you want are the div elements that are immediately adjacent siblings of a given h3. You can do this with the following xpath
h3_tags = driver.find_elements(By.XPATH, "//h3[@class='privacy-type__purpose-heading']")
xpath = "./following-sibling::div[last() = count(preceding-sibling::h3[1]/following-sibling::div)]/descendant::li"
for h3 in h3_tags:
print(h3.text.upper())
print('\n'.join( [li.text for li in h3.find_elements(By.XPATH, xpath)] ))
print()
Output
APP FUNCTIONALITY
Customer Support
THIRD-PARTY ADVERTISING
Advertising Data
ANALYTICS
Product Interaction
Advertising Data
APP FUNCTIONALITY
User ID
Device ID
Crash Data
Performance Data
Other Diagnostic Data
To understand what that xpath means, we can isolate two parts:
./following-sibling::div[last()]
selects the last div which comes after the h3 element (current node). Notice that last() is simply a number, corresponding to the position of the last element, so if there are four div then last()=4 and we obtain div[4] which is in fact the fourth div.
div[last() = count(preceding-sibling::h3[1]/following-sibling::div)]
compares the position of the last div with the count of preceding sibling div elements that come after the first h3 sibling of the selected div. If the position of the last div is the same as the count of preceding div elements, it means that the selected div is the only div following the h3 element.