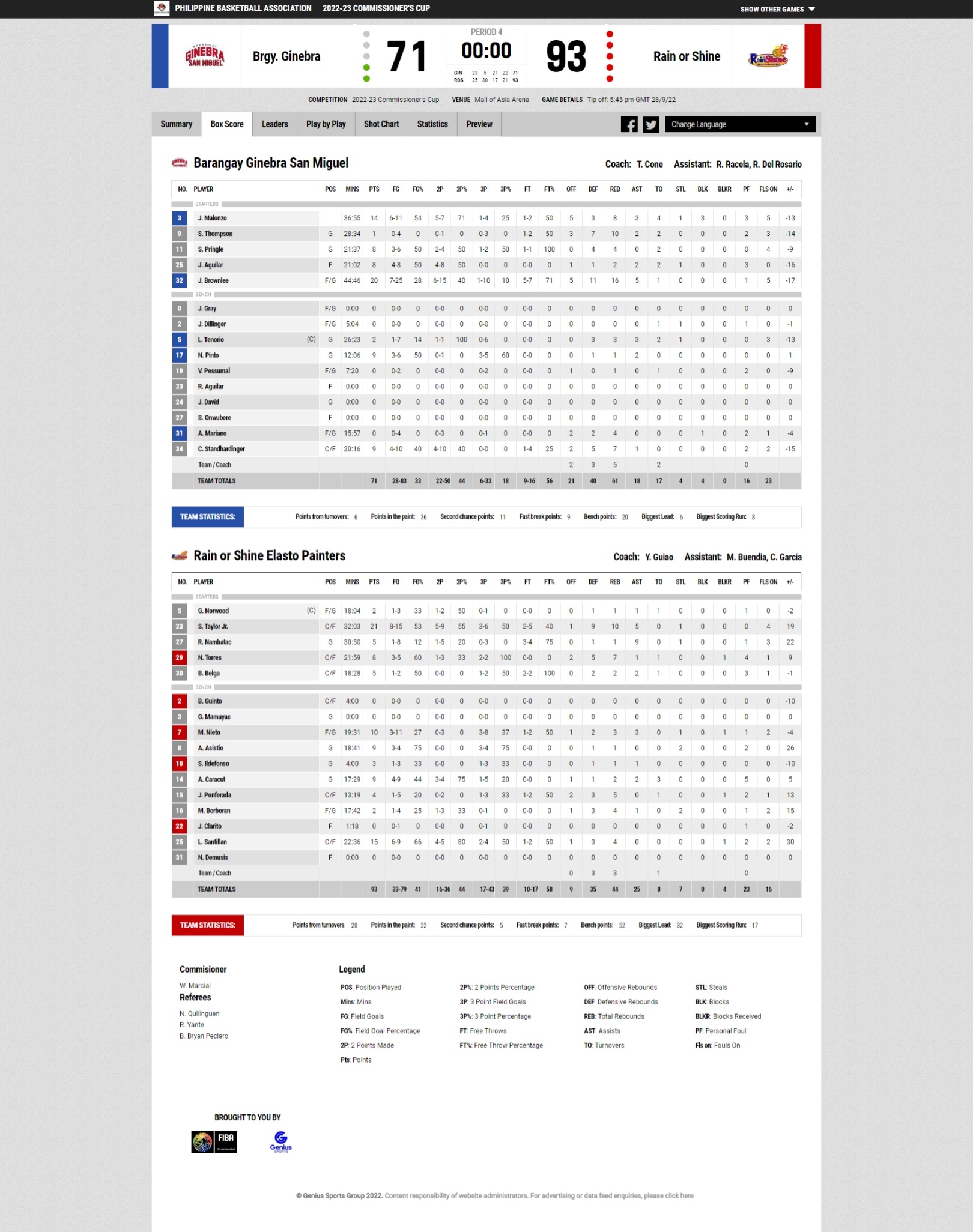
i am barely a beginner at python and i would like to have a data set of my favorite local basketball team, that's why i search for a code scraping fiba stats box score , i found one here on stackoverflow and i tried to edit the headers but it just generates an empty csv file, wondering if anyone could help my edit the code below and scrape box score of each team
import requests
from bs4 import BeautifulSoup
import pandas
stats_basic = ['NO.', 'PLAYER', 'POS', 'MINS', 'PTS', 'FG', 'FG%', '2P', '2P%', '3P', '3P%', 'FT', 'FT%', 'OFF', 'DEF', 'REB', 'AST', 'TO', 'STL', 'BLK', 'BLKR', 'PF', 'FLS ON', ' /-']
#stats_adv = ['TS%', 'eFG%', '3PAr', 'FTr', 'ORB%', 'DRB%', 'TRB%', 'AST%', 'STL%', 'BLK%', 'TOV%', 'USG%', #'ORtg', 'DRtg', 'BPM']
url_boxscore = "https://fibalivestats.dcd.shared.geniussports.com/u/PBA/2145647/bs.html"
stats1 = []
r = requests.get(url_boxscore)
c = r.content
soup = BeautifulSoup(c, "html.parser")
box_scores_content = soup.find_all("div",{"id":"content"})
d = {}
for item in box_scores_content:
for stat in stats_basic:
d[stat] = (item.find_all("td",{"data-stat":"fg"})[11].text)
stats1.append(d)
df=pandas.DataFrame(stats1)
df.to_csv("ginebra.csv")
CodePudding user response:
Data is rendered from external source, so you won't get it in your response and BeautifulSoup could not find it.
Take a look into your browsers dev tools and check the xhr tab - you could pull the data and extract needed info from a JSON.
Example
Results for first team:
import requests
import pandas as pd
pd.DataFrame(
requests.get('https://fibalivestats.dcd.shared.geniussports.com/data/2145647/data.json').json()['tm']['1']['pl'].values()
)
CodePudding user response:
I was able to reproduce your problem, i will not give you the full answer beacuse i really want you to figure it out by yourself since you are a beginner but i will point you to the right direction.
While i was debugging i printed the variable box_scores_content and found out it was empty, than i moved forward and looked in the BeautifulSoup documentation for find_all() and find() method and found really cool stuff which you can dig on your
own in this link: https://www.crummy.com/software/BeautifulSoup/bs4/doc/.
Your problem is you are not using find_all() the right way for your porpuse and also you are not scrapping the right attributes.
Using web tools or Right click and then inspect on the page i used CTRL SHIFT C i clicked on the main table and saw how it is defined in the HTML page you gave us, i then saw i need to use find_all("table") and use another filters to extract your wanted data.
When web scrapping it is important to know how to use webtools and reading the doc of the libraries you use so you could use them the right way.
Im sure youll figure it out from here :)