I have to use a particular column as 2 different condition in same case statement with count distinct in SQL Bigquery, Please let me know how
Data:
cus month col1
1 202207 A
1 202207 Z
2 202209 B
2 202210 Z
2 202211 A
3 202211 B
4 202212 Z
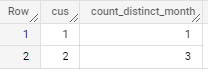
Desired output :
cus count_distinct_month
1 1
2 3
Exisiting sql query:
count(distinct (case when (month >= 202207 and month <= 202301) and col1 in ('A','B','C','D','E','F') and (col1 ='Z') then month end)) as count_distinct_month
This query is throwing me 0 result, please help on the same
CodePudding user response:
Filter the rows of the table with your conditions for the month and col1 and aggregate:
SELECT cus,
COUNT(DISTINCT month) AS count_distinct_month
FROM tablename
WHERE month >= 202207 AND month <= 202301 AND col1 IN ('A', 'B', 'C', 'D', 'E', 'F', 'Z')
GROUP BY cus
HAVING COUNTIF(col1 ='Z') > 0 AND COUNT(DISTINCT col1) > 1;
The HAVING clause makes sure that for each cus in the results there is at least 1 row with col1 ='Z' and at least another row with col1 IN ('A', 'B', 'C', 'D', 'E', 'F').
CodePudding user response:
consider below approach
select cus, count(distinct month) as count_distinct_month
from your_table
where month between 202207 and 202301
and col1 in ('A','B','C','D','E','F', 'Z')
group by cus
having countif(col1 ='Z') > 0 and countif(col1 in ('A','B','C','D','E','F')) > 0
if applied to sample data in your question - output is