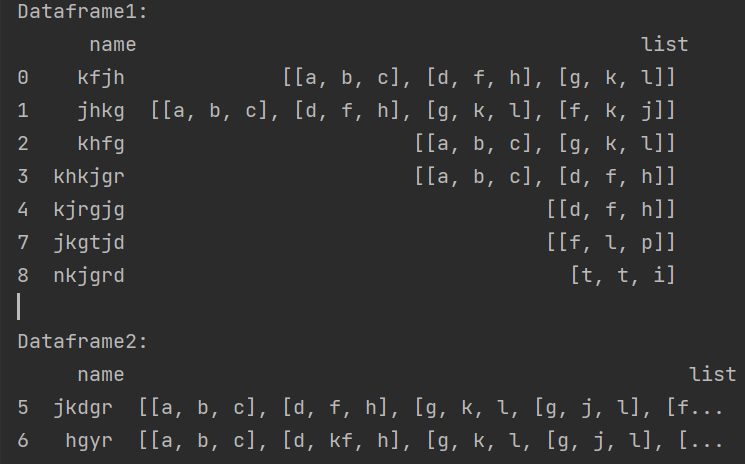
The dataframe I have, df:
name list
0 kfjh [[a,b,c],[d,f,h],[g,k,l]]
1 jhkg [[a,b,c],[d,f,h],[g,k,l],[f,k,j]]
2 khfg [[a,b,c],[g,k,l]]
3 khkjgr [[a,b,c],[d,f,h]]
4 kjrgjg [[d,f,h]]
5 jkdgr [[a,b,c],[d,f,h],[g,k,l, [g,j,l],[f,l,p]]
6 hgyr [[a,b,c],[d,kf,h],[g,k,l, [g,j,l],[f,l,p]]
7 jkgtjd [[f,l,p]]
8 nkjgrd [t,t,i]
if the list has more than 4 list, then I would like to get df1. The desired output, df1 :
name list
5 jkdgr [[a,b,c],[d,f,h],[g,k,l, [g,j,l],[f,l,p]]
6 hgyr [[a,b,c],[d,kf,h],[g,k,l, [g,j,l],[f,l,p]]
and, df2:
name list
0 kfjh [[a,b,c],[d,f,h],[g,k,l]]
1 jhkg [[a,b,c],[d,f,h],[g,k,l],[f,k,j]]
2 khfg [[a,b,c],[g,k,l]]
3 khkjgr [[a,b,c],[d,f,h]]
4 kjrgjg [[d,f,h]]
7 jkgtjd [[f,l,p]]
8 nkjgrd [t,t,i]
CodePudding user response:
You can do something like this if column list is a string. if the list is list of lists with every element as a string, you can change the split for only len of the array and compare to 4 to do it.
import pandas as pd
data = {
'name': ['kfjh', 'jhkg', 'khfg', 'khkjgr', 'kjrgjg', 'jkdgr', 'hgyr', 'jkgtjd', 'nkjgrd'],
'list': ['[[a,b,c],[d,f,h],[g,k,l]]', '[[a,b,c],[d,f,h],[g,k,l],[f,k,j]]', '[[a,b,c],[g,k,l]]', '[[a,b,c],[d,f,h]]', '[[d,f,h]]', '[[a,b,c],[d,f,h],[g,k,l],[g,j,l],[f,l,p]]', '[[a,b,c],[d,f,h],[g,kf,l],[g,j,l],[f,l,p]]', '[[f,l,p]]', '[t,t,i]']
}
df = pd.DataFrame(data)
df['drop'] = df.apply(lambda row : 'no' if len(row['list'].split('[')) > 6 else 'yes', axis = 1)
df1 = df.loc[df['drop'] == 'yes']
df2 = df.loc[df['drop'] == 'no']
df1 = df1.drop(columns=['drop'])
df2 = df2.drop(columns=['drop'])
print(df1)
print(df2)
CodePudding user response:
Try this:
from ast import literal_eval
df.list.apply(literal_eval)
CodePudding user response:
You can use map(len) to give the number of elements in a List in a column. So you could use:
df1 = df[df['list'].map(len) > 4]
df2 = df[df['list'].map(len) <= 4]
which gives the two sets of results you present
CodePudding user response:
Simply iterate through the first dataframe, get list length by counting nested lists in a recursive method and add the new corresponding rows to another dataframe:
import pandas as pd
def count_lists(l):
return sum(1 count_lists(i) for i in l if isinstance(i,list))
data = {'name': ['kfjh', 'jhkg', 'khfg', 'khkjgr', 'kjrgjg', 'jkdgr', 'hgyr', 'jkgtjd', 'nkjgrd'],
'list': [[['a','b','c'],['d','f','h'],['g','k','l']], [['a','b','c'],['d','f','h'],['g','k','l'],['f','k','j']],
[['a','b','c'],['g','k','l']], [['a','b','c'],['d','f','h']], [['d','f','h']],
[['a','b','c'],['d','f','h'],['g','k','l', ['g','j','l'],['f','l','p']]],
[['a','b','c'], ['d','kf','h'],['g','k','l', ['g','j','l'], ['f','l','p']]],[['f','l','p']],['t','t','i']]}
dframe = pd.DataFrame(data)
dframe1 = pd.DataFrame()
dframe2 = pd.DataFrame()
for i, j in dframe.iterrows():
if count_lists(j)-1 > 4:
dframe2 = dframe2.append(dframe.iloc[i])
else:
dframe1 = dframe1.append(dframe.iloc[i])
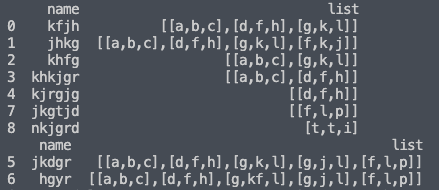
print("Dataframe1:\n", dframe1, "\n")
print("Dataframe2:\n", dframe2)
Result: