I have a function that is driving me crazy and I am supposed to use only PySpark.
The table below is a representation of the data:
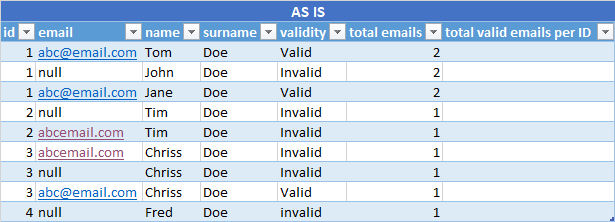
There are IDs, Name, Surname and Validity over which I can partition by, but I should lit the value of the percentage of emails that are set correctly by ID.
Like the image below:
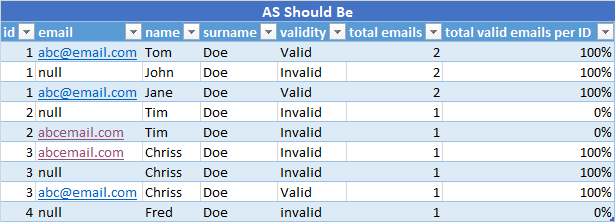
How can I solve this problem?
window = Window.partitionBy("ID", "email", "name", "surname", "validity").orderBy(col("ID").desc())
df = df.withColumn("row_num", row_number().over(window))
df_new = df.withColumn("total valid emails per ID", df.select("validity").where(df.validity == "valid" & df.row_num == 1)).count()
CodePudding user response:
Something like:
win = Window.partitionBy("ID", "email", "name", "surname")
df = df.withColumn(
"pct_valid",
F.sum(F.when(F.col("validity") == "Valid", 1).otherwise(0)).over(win)
/ F.col("total emails"),
)
CodePudding user response:
This would work:
df.withColumn("ValidAsNumber", F.when(F.col("Validity") == "Valid", 1).otherwise(0))\
.withColumn("TotalValid", F.sum("ValidAsNumber").over(Window.partitionBy("ID")))\
.withColumn("PercentValid", F.expr("(TotalValid/TotalEmails)*100")).show()
Input:

Output (I kept the intermediate columns for understanding, you can drop them):
