I have a list of dictionaries organized as such:
listofdictionaries = [{'key1': (A, B, C), 'key2':[1, 2, 3]},
{'key1': (AA, BB, CC), 'key2':[1, 2, 3]},
{'key1': (AAA, BBB, CCC), 'key2':[4, 5, 6]}]
This list's first and second items have an equivalent value for key2. The third item has a different value for key2. Still using Python, I want the columns organized as such:
| Group 1 | Group 1 Items | Group 2 | Group 2 Items |
|---|---|---|---|
| [1, 2, 3] | (A, B, C) | [4, 5, 6] | (AAA, BBB, CCC) |
| (AA, BB, CC) |
In addition I would like the output to be a .csv file.
CodePudding user response:
It is possible in Excel, but probably using FILTERXML is possible a shorter way, but it is not available for Excel Web, which is the version I use.
It is a good candidate to use a recursive function to do multiple substitutions. Please check my answer to the question: 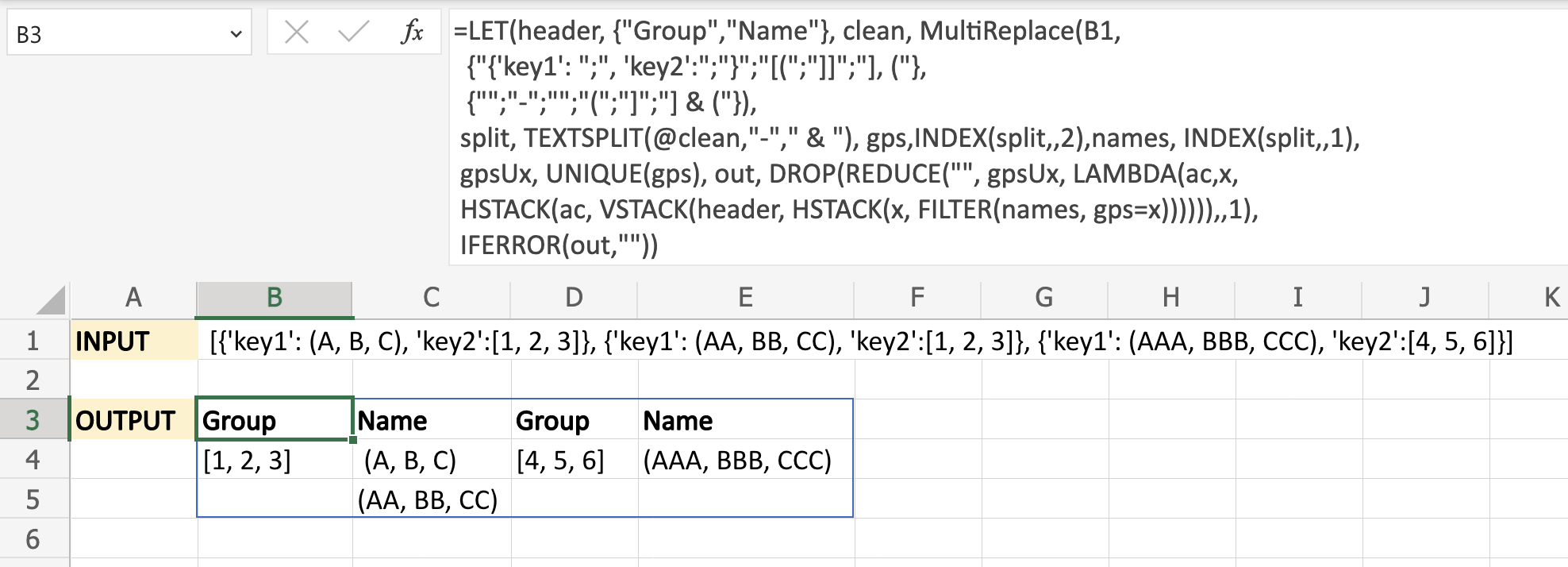
You can check the output of each name variable: clean, split, to see the intermediate result. Once we have the information in array format (split), then we apply DROP/REDUCE/HSTACK pattern. Check my answer to the question: 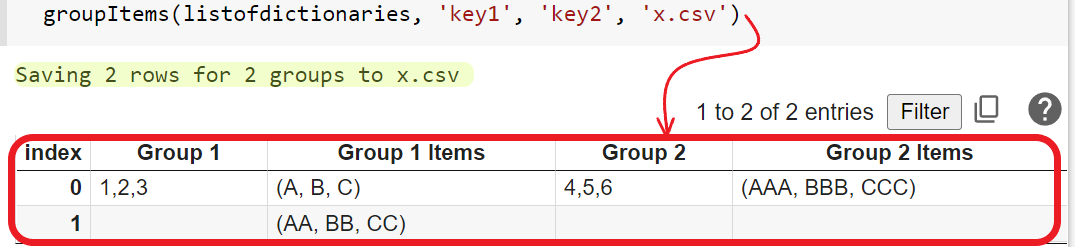
You could also get it in this format if you change the function to
{kind=link}
def groupItems(dictList, itemsFrom, groupBy, saveTo=None):
ik, gk = itemsFrom, groupBy
groups = {str(d.get(gk)): d.get(gk) for d in dictList}
itemsList = [ [d.get(ik) for d in dictList if str(d.get(gk))==g]
for g in groups ]
maxRows = max(len(li) for li in itemsList) if groups else 0
rdf = pandas.DataFrame({
f'Group {gi}': [groups[g]] [None] [f'Group {gi} Items']
li [None]*(maxRows-len(li))
for gi, (g, li) in enumerate(zip(groups.keys(), itemsList), 1)
})
if saveTo:
print('Saving', maxRows 4, 'rows for', len(groups),'groups to', saveTo)
rdf.to_csv(saveTo, index=False)
return rdf