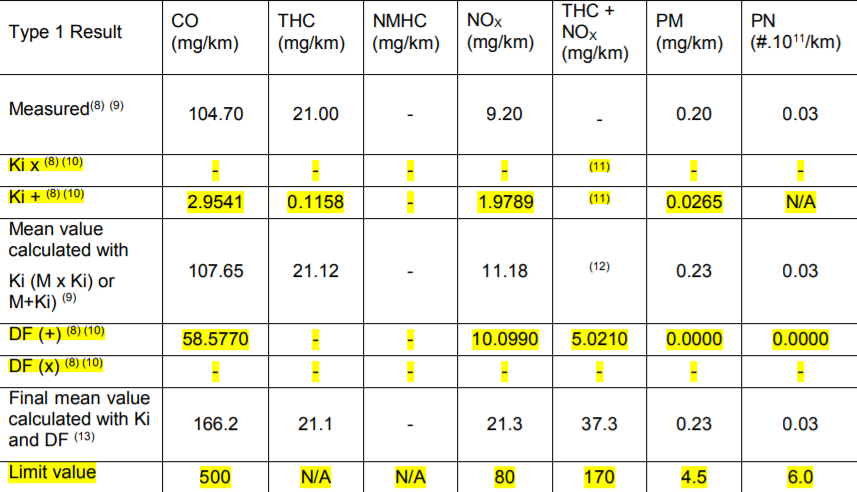
I have the below python dictionary.The decimal values of the dict can change, but the string values remains constant. The structure of the dictionary also would be the same. In such a scenario, is it possible to build a dataframe (in the format shown below) from the dictionary?
Python dictionary:
d1=
{'Type 1 Result': 'CO (mg/km) THC (mg/km) NMHC (mg/km) NOX (mg/km) THC NOX (mg/km) PM (mg/km) PN (#.1011/km) Measured(8) (9) 104.70 21.00 - 9.20 - 0.20 0.03 Ki x (8) (10) - - - - (11) - - Ki (8) (10) 2.9541 0.1158 - 1.9789 (11) 0.0265 N/A Mean value calculated with Ki (M x Ki) or M Ki) (9) 107.65 21.12 - 11.18 (12) 0.23 0.03 DF ( ) (8) (10) 58.5770 - - 10.0990 5.0210 0.0000 0.0000 DF (x) (8) (10) - - - - - - - Final mean value calculated with Ki and DF (13) 166.2 21.1 - 21.3 37.3 0.23 0.03 Limit value 500 N/A N/A 80 170 4.5 6.0'}
Required Dataframe Format:
CodePudding user response:
This is indeed possible. Because your dictionary does not contain more than 1 key / value pair, I would suggest to merge it into a string:
my_string = f"{list(d1.keys())[0]} {list(d1.values())[0]}"
Next, you can flag the "constant" values of columns and rows:
COL_ROWS = ["Type 1 Result", "CO \(mg/km\)", "THC \(mg/km\)", "NMHC \(mg/km\)", "NOX \(mg/km\)", "THC \ PM \(mg/km\)", "PN \(#\.1011/km\)", "Measured\(8\) \(9\)", "Ki x \(8\) \(10\)", "Ki \ \(8\) \(10\)", "Mean value calculated with Ki \(M x Ki\) or M\ Ki\) \(9\)", "DF \(\ \) \(8\) \(10\)", "DF \(x\) \(8\) \(10\)", "Final mean value calculated with Ki and DF \(13\)", "Limit value"]
Subsequently, if you remove the strings that appear in COL_ROWS from my_string. Using: Remove substring from string if substring is contained in a list:
import re
p = re.compile('|'.join(COL_ROWS ))
my_string = p.sub("", my_string).strip()
You will obtain a string where each value is separated by a space. You can then simply do elements = my_string.split() to have them neatly in a list.
Finally, you simply have to implement the logic to initialize a DataFrame using that data by iterating over the columns and elements.
A possibility is:
# separate headers from content
COLS, CONTENT = COL_ROWS[:8], COL_ROWS[8:]
all_cols = {}
for i in range(len(CONTENT)):
# store column name
col = [CONTENT[i].replace('\\', '']
# add values
col = el[i * 7: (i 1) * 7]
# store in dict
all_cols[COLS[i]] = col
# initialize DF with dict
final_df = pd.DataFrame(all_cols)