String 1:
[impro:0,grp:00,time:0xac,magic:0x00ac] CAR<7:5>|BIKE<4:0>,orig:0x8c,new:0x97
String 2:
[impro:0,grp:00,time:0xbc,magic:0x00bc] CAKE<4:0>,orig:0x0d,new:0x17
In string 1, I want to extract CAR<7:5 and BIKE<4:0,
In string 2, I want to extract CAKE<4:0
Any regex for this in Python?
CodePudding user response:
You can use \w <[^>]
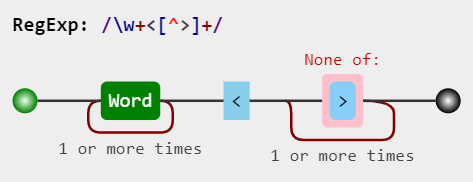
- \w matches any word character (equivalent to [a-zA-Z0-9_])
- matches the previous token between one and unlimited times, as many times as possible, giving back as needed (greedy).
- < matches the character <
- [^>] Match a single character not present in the list
- matches the previous token between one and unlimited times, as many times as possible, giving back as needed (greedy)
CodePudding user response:
We can use re.findall here with the pattern (\w .*?)>:
inp = ["[impro:0,grp:00,time:0xac,magic:0x00ac] CAR<7:5>|BIKE<4:0>,orig:0x8c,new:0x97", "[impro:0,grp:00,time:0xbc,magic:0x00bc] CAKE<4:0>,orig:0x0d,new:0x17"]
for i in inp:
matches = re.findall(r'(\w <.*?)>', i)
print(matches)
This prints:
['CAR<7:5', 'BIKE<4:0']
['CAKE<4:0']
CodePudding user response:
In the first example, the BIKE part has no leading space but a pipe char.
A bit more precise match might be asserting either a space or pipe to the left, and match the digits separated by a colon and assert the > to the right.
(?<=[ |])[A-Z] <\d :\d (?=>)
In parts, the pattern matches:
(?<=[ |])Positive lookbehind, assert either a space or a pipe directly to the left[A-Z]Match 1 chars A-Z<\d :\dMatch<and 1 digits betqeen:(?=>)Positive lookahead, assert>directly to the right
Or the capture group variant:
(?:[ |])([A-Z] <\d :\d)>