I have a dataframe, which has some items title for example
ratings_dict = {
"TYPE": ["Testing","Headphone","Iphone","AC","Laptop","Monitor"],
}
df = pd.DataFrame(ratings_dict)
Want to count the value based on a given list:
Search_history=['test','phone','lap','testing','tes','iphone','Headphone','head','Monitor','ac']
Expected output:
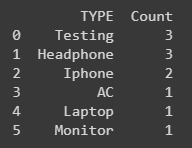
Note: In the case, the word "phone" is matched with 2 values in the dataframe "Headphone" and "Iphone" then Count will increment for both.
Any suggestion or code snippet will be helpful.
CodePudding user response:
You need to convert everything to lowercase then count the number of times a TYPE is a substring of a search history item and vice versa
import pandas as pd
ratings_dict = {
"TYPE": ["Testing","Headphone","Iphone","AC","Laptop","Monitor"],
}
df = pd.DataFrame(ratings_dict)
Search_history=['test','phone','lap','testing','tes','iphone','Headphone','head','Monitor','ac']
# convert everything to lower case
Search_history = [ x.lower() for x in Search_history]
df['TYPE'] = [ x.lower() for x in df.TYPE]
# count up the number of times one of the TYPEs is a substring of a Search_history or a Search_history is a substring of a TYPE
df['count'] = [ sum( x in y or y in x for y in Search_history) for x in df.TYPE]
CodePudding user response:
It's up to you to define what conditions make sense, your question is a bit too loose. You could either check if the values match, of you could convert some list values into default ones before they are checked as well