I have the following DataFrame containing the date format - yyyyMMddTHH:mm:ss UTC
Data Preparation
sparkDF = sql.createDataFrame([("20201021T00:00:00 0530",),
("20211011T00:00:00 0530",),
("20200212T00:00:00 0300",),
("20211021T00:00:00 0530",),
("20211021T00:00:00 0900",),
("20211021T00:00:00-0500",)
]
,['timestamp'])
sparkDF.show(truncate=False)
----------------------
|timestamp |
----------------------
|20201021T00:00:00 0530|
|20211011T00:00:00 0530|
|20200212T00:00:00 0300|
|20211021T00:00:00 0530|
|20211021T00:00:00 0900|
|20211021T00:00:00-0500|
----------------------
I m aware of the date format to parse and convert the values to DateType
Timestamp Parsed
sparkDF.select(F.to_date(F.col('timestamp'),"yyyyMMdd'T'HH:mm:ss 0530").alias('timestamp_parsed')).show()
----------------
|timestamp_parsed|
----------------
| 2020-10-21|
| 2021-10-11|
| null|
| 2021-10-21|
| null|
| null|
----------------
As you can see , its specific to 0530 strings , I m aware of the fact that I can use multiple patterns and coalesce the first non-null values
Multiple Patterns & Coalesce
sparkDF.withColumn('p1',F.to_date(F.col('timestamp'),"yyyyMMdd'T'HH:mm:ss 0530"))\
.withColumn('p2',F.to_date(F.col('timestamp'),"yyyyMMdd'T'HH:mm:ss 0900"))\
.withColumn('p3',F.to_date(F.col('timestamp'),"yyyyMMdd'T'HH:mm:ss-0500"))\
.withColumn('p4',F.to_date(F.col('timestamp'),"yyyyMMdd'T'HH:mm:ss 0300"))\
.withColumn('timestamp_parsed',F.coalesce(F.col('p1'),F.col('p2'),F.col('p3'),F.col('p4')))\
.drop(*['p1','p2','p3','p4'])\
.show(truncate=False)
---------------------- ----------------
|timestamp |timestamp_parsed|
---------------------- ----------------
|20201021T00:00:00 0530|2020-10-21 |
|20211011T00:00:00 0530|2021-10-11 |
|20200212T00:00:00 0300|2020-02-12 |
|20211021T00:00:00 0530|2021-10-21 |
|20211021T00:00:00 0900|2021-10-21 |
|20211021T00:00:00-0500|2021-10-21 |
---------------------- ----------------
Is there a better way to accomplish this, as there might be a bunch of other UTC within the data source, is there a standard UTC TZ available within Spark to parse all the cases
CodePudding user response:
i think you have got the 2nd argument of your to_date function wrong which is causing null values in your output
the 530 in your timestamp is the Zulu value which just denotes how many hours and mins ahead (for ) or behind (for -) the current timestamp is withrespect to UTC.
Please refer to the response by Basil here 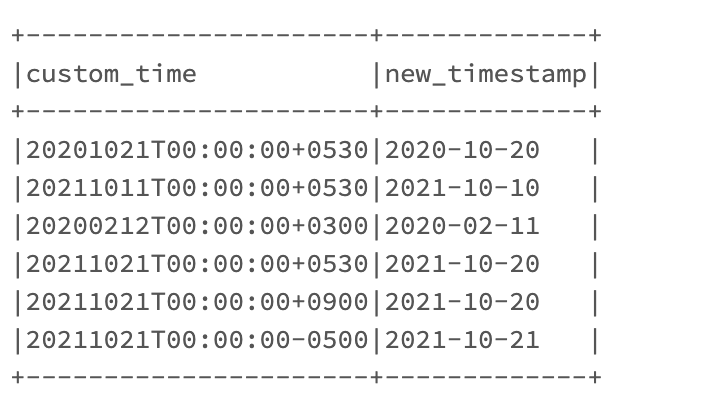
CodePudding user response:
You can usually use x, X or Z for offset pattern as you can find on Spark date pattern documentation page. You can then parse your date with the following complete pattern: yyyyMMdd'T'HH:mm:ssxx
However, if you use those kind of offset patterns, your date will be first converted in UTC format, meaning all timestamp with a positive offset will be matched to the previous day. For instance "20201021T00:00:00 0530" will be matched to 2020-10-20 using to_date with the previous pattern.
If you want to get displayed date as a date, ignoring offset, you should first extract date string from complete timestamp string using regexp_extract function, then perform to_date.
If you take your example "20201021T00:00:00 0530", what you want to extract with a regexp is 20201021 part and apply to_date on it. You can do it with the following pattern: ^(\\d ). If you're interested, you can find how to build other patterns in java's Pattern documentation.
So your code should be:
from pyspark.sql import functions as F
sparkDF.select(
F.to_date(
F.regexp_extract(F.col('timestamp'), '^(\\d )', 0), 'yyyyMMdd'
).alias('timestamp_parsed')
).show()
And with your input you will get:
----------------
|timestamp_parsed|
----------------
|2020-10-21 |
|2021-10-11 |
|2020-02-12 |
|2021-10-21 |
|2021-10-21 |
|2021-10-21 |
----------------
CodePudding user response:
You can create "udf" in spark and use it. Below is the code in scala.
import spark.implicits._
//just to create the dataset for the example you have given
val data = Seq(
("20201021T00:00:00 0530"),
("20211011T00:00:00 0530"),
("20200212T00:00:00 0300"),
("20211021T00:00:00 0530"),
("20211021T00:00:00 0900"),
("20211021T00:00:00-0500"))
val dataset = data.toDF("timestamp")
val udfToDateUTC = functions.udf((epochMilliUTC: String) => {
val formatter = DateTimeFormatter.ofPattern("yyyyMMdd'T'HH:mm:ssZ")
val res = OffsetDateTime.parse(epochMilliUTC, formatter).withOffsetSameInstant(ZoneOffset.UTC)
res.toString()
})
dataset.select(dataset.col("timestamp"),udfToDateUTC(dataset.col("timestamp")).alias("timestamp_parsed")).show(false)
//output
---------------------- -----------------
|timestamp |timestamp_parsed |
---------------------- -----------------
|20201021T00:00:00 0530|2020-10-20T18:30Z|
|20211011T00:00:00 0530|2021-10-10T18:30Z|
|20200212T00:00:00 0300|2020-02-11T21:00Z|
|20211021T00:00:00 0530|2021-10-20T18:30Z|
|20211021T00:00:00 0900|2021-10-20T15:00Z|
|20211021T00:00:00-0500|2021-10-21T05:00Z|
---------------------- -----------------