Good time a day. I have a table with data, which you can download by that link:
CodePudding user response:
I would not recommend iterating, but the fact that each sequential calculation depends on the result of the previous calculation complicates vectorization.
You would either use apply, which would in a way be looping over your rows, or you could explicitly loop over your rows and perform your calculation using .loc.
Consider the first 4 rows of your DF:
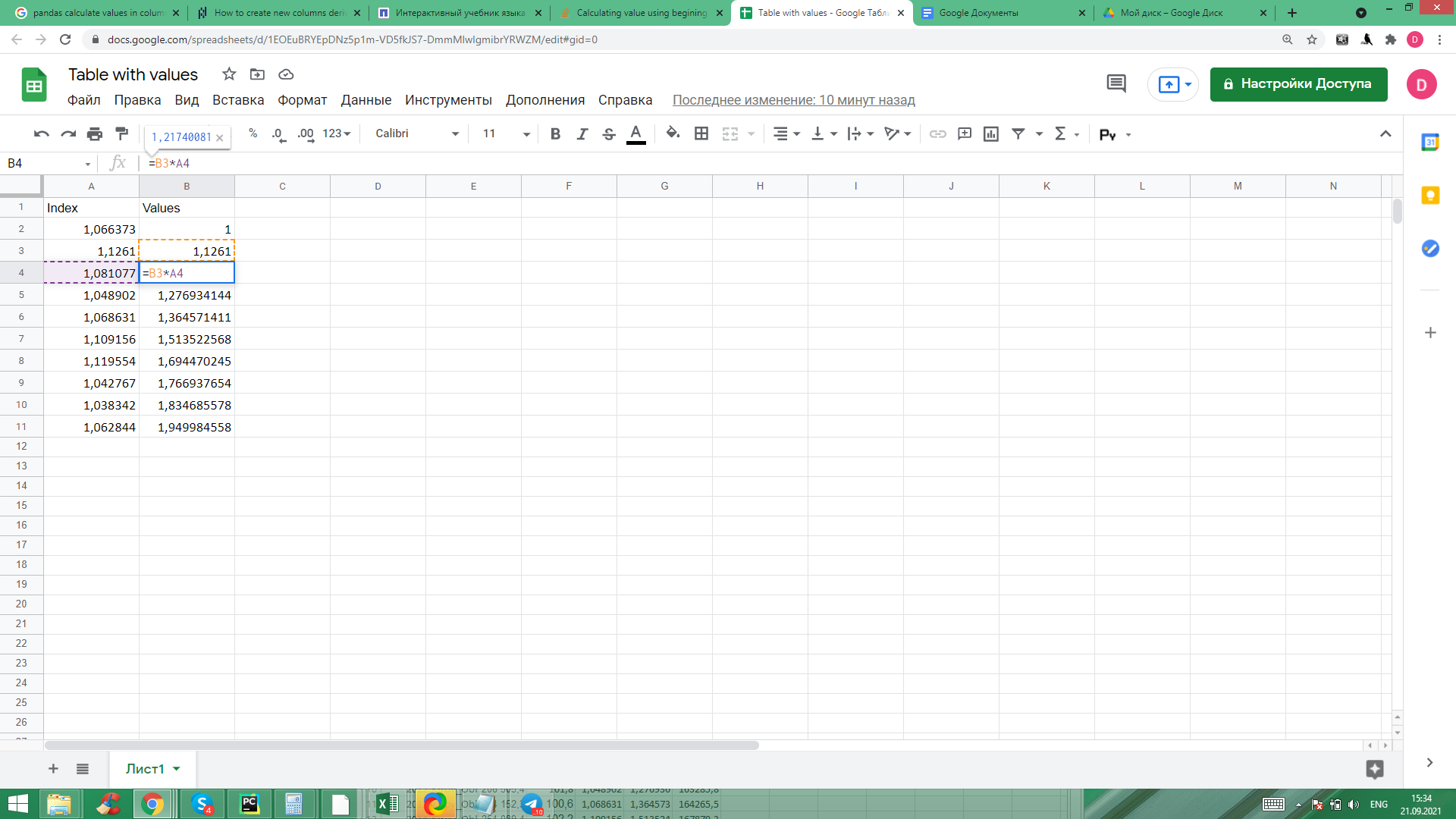
>>> df
Index Values
0 1.066373 1.0
1 1.126100 NaN
2 1.081077 NaN
3 1.048902 NaN
4 1.068631 NaN
for i in range(1, len(df)):
df.loc[i, 'Values'] = df.loc[i-1, 'Values'] * df.loc[i, 'Index']
Updates your Values column in your DF to:
Index Values
0 1.066373 1.000000
1 1.126100 1.126100
2 1.081077 1.217401
3 1.048902 1.276934
4 1.068631 1.364571
Some remarks:
- Make sure that your 'Index' column, is a column and not your index.
range(1,...)makes sure yourloopstarts fromindex1 and not 0.- I assume this will be slow if your
DFis large
CodePudding user response:
You can use the cumprod (cumulative product) method on the Index values, after replacing the first value by 1:
import pandas as pd
df = pd.DataFrame({'Index': [1.066373, 1.126100, 1.081077, 1.048902, 1.068631]})
df['Values'] = df.Index
df.Values[0] = 1
df.Values = df.Values.cumprod()
df
Index Values
0 1.066373 1.000000
1 1.126100 1.126100
2 1.081077 1.217401
3 1.048902 1.276934
4 1.068631 1.364571