I have a data frame like this:
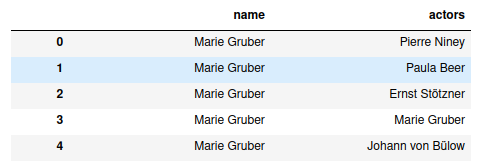
and the dataset in the CSV file is here.
this data was extracted from the IMDb dataset. but I have a problem, I could not be able to remove the actor's names which are repeated in the same row for example in row number 4 I want to drop 'Marie Gruber' in both name and actors column. I tried to use to apply and all conditions but always code consider it the same. like this code:
data[data['name'] != data['actors']]
CodePudding user response:
Trere are traling spaces for actors column, so first remove them by Series.str.strip:
data['actors'] = data['actors'].str.strip()
data[data['name'] != data['actors']]
Or use skipinitialspace=True in read_csv:
data = pd.read_csv(file, skipinitialspace=True)
data[data['name'] != data['actors']]
CodePudding user response:
Use pandas.dataframe.drop function.
data.drop(data[data.apply(lambda x: x['name'] in x['actors'], axis = 1)].index)