I have a dataframe that looks like this
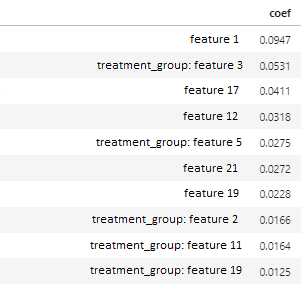
Each row has its own copy with the 'treatment_group' prefix but with a different coefficient. How can I sum these rows by coef across the entire dataframe using the following logic: sum = treatment_group: feature 19 feature 19?
CodePudding user response:
You can use split with select last value, it working for any values with aggregate sum:
df.groupby(df.index.str.split(':').str[-1]).sum()
Or use replace:
df.groupby(df.index.str.replace('treatment_group:', '', regex=True)).sum()
Like mentioned @mozway in comments - is possible extract last numbers in index (added expand=False for return Series):
df.groupby(df.index.str.extract('(\d )$', expand=False)).sum()
CodePudding user response:
Just do:
df.groupby(df.index.str.extract('(\d )$')).sum()