I have a dataframe:
data = {'process': ['buying','selling','searhicng','repairing', 'preparing', 'selling','buying', 'searching', 'selling','searching'],
'type': ['in_progress','in_progress','end','in_progress', 'end', 'in_progress','in_progress', 'end', 'in_progress','end'],
'country': ['usa',np.nan, 'usa','ghana', np.nan,'end','portugal', np.nan, np.nan,'england'],
'id': ['022','022','022', '011','011', '011','011', '011', '011','011'],
'lag': ['00:00:10.042721','00:00:00.042721','00:00:05.042721','00:10:00.042721','00:00:00.042721','00:00:00.042721','00:00:50.042721','00:00:00.042721','00:00:00.042721','00:00:00.042721'],
'created': ['2021-07-01','2021-07-02','2021-07-03','2021-07-04','2021-07-05','2021-07-06','2021-07-06','2021-07-08','2021-07-09','2021-07-10'],
'next_created': ['2021-07-01','2021-07-02','2021-07-03','2021-07-04','2021-07-05','2021-07-06','2021-07-07','2021-07-08','2021-07-09','2021-07-10']
}
df = pd.DataFrame(data, columns = ['process','type','country', 'id','lag','created','next_created'])
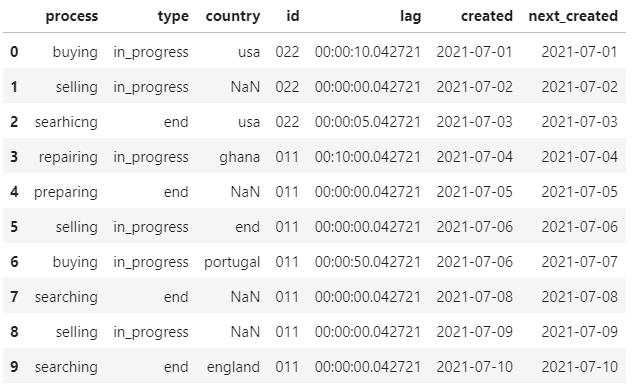
I need to concatenate consecutive rows by the process column for each group by id, which have lag less than one second, write the value of the first row to created, and created_next the value of the last line.
Can anyone see the problem, i don't understand how i can use groupby in this situation.
I guess that i need to use cumsum(), but i don't know what i can use in the ??? place
df['lag'].shift(1).???.cumsum()
Output result
CodePudding user response:
You can try:
# Convert to timedelta to facilitate checking of within one second
df['lag'] = pd.to_timedelta(df['lag'])
# Grouping by `lag` difference is less than one second within the same `id`
group = df['lag'].diff().abs().gt(np.timedelta64(1, 's')).groupby(df['id']).cumsum()
# Group by `id` and newly created grouping and then aggregate
(df.groupby(['id', group], as_index=False, sort=False)
.agg({'process': lambda x: ' '.join(x), # concatenate consecutive rows within total grouping
'type': 'first',
'country': lambda x: x.iloc[0], # get first entry including `NaN`
'id': 'first',
'lag': 'first',
'created': 'first', # get first entry
'next_created': 'last' # get last entry
})
)
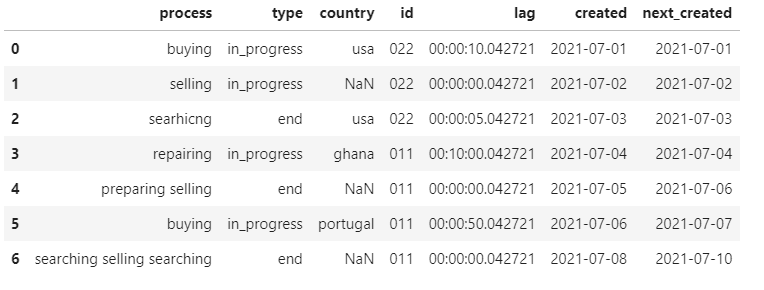
Result:
process type country id lag created next_created
0 buying in_progress usa 022 0 days 00:00:10.042721 2021-07-01 2021-07-01
1 selling in_progress NaN 022 0 days 00:00:00.042721 2021-07-02 2021-07-02
2 searhicng end usa 022 0 days 00:00:05.042721 2021-07-03 2021-07-03
3 repairing in_progress ghana 011 0 days 00:10:00.042721 2021-07-04 2021-07-04
4 preparing selling end NaN 011 0 days 00:00:00.042721 2021-07-05 2021-07-06
5 buying in_progress portugal 011 0 days 00:00:50.042721 2021-07-06 2021-07-07
6 searching selling searching end NaN 011 0 days 00:00:00.042721 2021-07-08 2021-07-10