I'm trying to use ggplot to plot my word frequency rankings from Quanteda. Works passing the 'frequency' variable to plot but I want a nicer graph.
ggplot needs two variables for aes. I've tried seq_along as suggested on a somewhat similar thread but the graph draws nothing.
ggplot(word_list, aes(x = seq_along(freqs), y = freqs, group = 1))
geom_line()
labs(title = "Rank Frequency Plot", x = "Rank", y = "Frequency")
Any input appreciated!
symptoms_corpus <- corpus(X$TEXT, docnames = X$id )
summary(symptoms_corpus)
# print text of any element of the corpus by index
cat(as.character(symptoms_corpus[6500]))
# Create Document Feature Matrix
Symptoms_DFM <- dfm(symptoms_corpus)
Symptoms_DFM
# sum columns for word counts
freqs <- colSums(Symptoms_DFM)
# get vocabulary vector
words <- colnames(Symptoms_DFM)
# combine words and their frequencies in a data frame
word_list <- data.frame(words, freqs)
# re-order the wordlist by decreasing frequency
word_indexes <- order(word_list[, "freqs"], decreasing = TRUE)
word_list <- word_list[word_indexes, ]
# show the most frequent words
head(word_list, 25)
#plot
ggplot(word_list, aes(x = seq_along(freqs), y = freqs, group = 1))
geom_line()
labs(title = "Rank Frequency Plot", x = "Rank", y = "Frequency")
By nicer graph I mean that using the base 'plot' function below works and illustrates the ranking distribution, but this takes only one variable. ggplot needs two and that's where the issue arises for me. The ggplot code will draw the graph but no data displayed.
plot(word_list$freqs , type = "l", lwd=2, main = "Rank frequency Plot", xlab="Rank", ylab ="Frequency")
Example dataset below:
first_column <- c("the","patient", "arm", "rash", "tingling", "was", "in", "not")
second_column <- c("4116407", "3599537", "2582586", "1323883", "1220894", "1012042", "925339", "822150")
word_list2 <- data.frame(first_column, second_column)
colnames(word_list2) <- c=("word", "freqs")
CodePudding user response:
Here's a tidier, and reproducible demonstration of your plot, using the built-in corpus.
library("quanteda")
## Package version: 3.1.0
## Unicode version: 13.0
## ICU version: 69.1
## Parallel computing: 12 of 12 threads used.
## See https://quanteda.io for tutorials and examples.
symptoms_corpus <- data_corpus_inaugural
Symptoms_DFM <- tokens(symptoms_corpus) %>%
dfm()
Better to use quanteda.textstats::textstat_frequency() here:
# create frequency table
library("quanteda.textstats")
word_list <- textstat_frequency(Symptoms_DFM)
head(word_list, 25)
## feature frequency rank docfreq group
## 1 the 10183 1 59 all
## 2 of 7180 2 59 all
## 3 , 7173 3 59 all
## 4 and 5406 4 59 all
## 5 . 5155 5 59 all
## 6 to 4591 6 59 all
## 7 in 2827 7 59 all
## 8 a 2292 8 58 all
## 9 our 2224 9 58 all
## 10 we 1827 10 58 all
## 11 that 1813 11 59 all
## 12 be 1502 12 59 all
## 13 is 1491 13 58 all
## 14 it 1398 14 59 all
## 15 for 1230 15 59 all
## 16 by 1091 16 59 all
## 17 have 1031 17 59 all
## 18 which 1007 18 57 all
## 19 not 980 19 58 all
## 20 with 970 20 58 all
## 21 as 966 21 58 all
## 22 will 944 22 57 all
## 23 this 874 23 59 all
## 24 i 871 24 58 all
## 25 all 836 25 59 all
Then plot it:
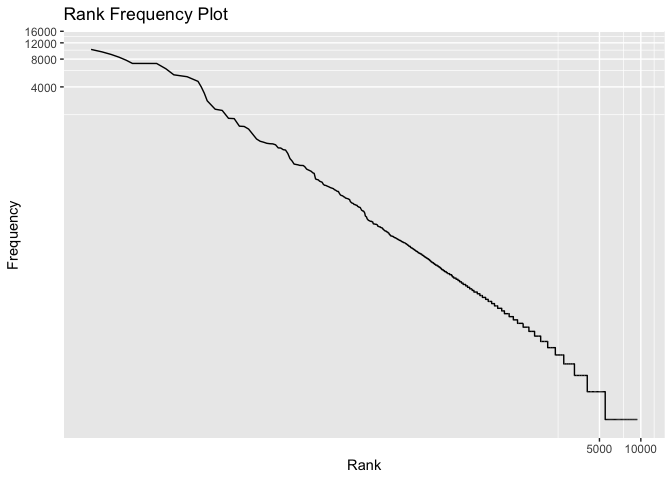
# Zipf's law plot
library("ggplot2")
ggplot(word_list, aes(x = seq_len(nrow(word_list)), y = frequency, group = 1))
geom_line()
coord_trans(y = "log10", x = "log10")
labs(title = "Rank Frequency Plot", x = "Rank", y = "Frequency")
CodePudding user response:
I am unsure of what you mean by a "nicer graph". Could you specify? It is not possible to reproduce the example by the code that you provided, because we do not have your dataset.
Perhaps you could simply add row numbers as the x-values as below. This produces an ordered graph
library(ggplot2)
word_list <- data.frame(freq = c(10, 12, 18, 19))
ggplot(word_list, aes(x = 1:nrow(word_list), y = freq, group = 1))
geom_line()
labs(title = "Rank Frequency Plot", x = "Rank", y = "Frequency")
CodePudding user response:
I needed to logarithmically scale, dataset is huge so wasn't appearing. Example above, @TrineCosmusNobel, pointed this out. Thanks. Updated code below:
ggplot(word_list, aes(x = 1:nrow(word_list), y = freqs, group = 1))
geom_line()
coord_trans(y ='log10', x='log10')
labs(title = "Rank Frequency Plot", x = "Rank", y = "Frequency")