I am working on a project regarding demand forecasting for pharmaceuticals.
So first of all:
The raw import data which used includes information of; import dates, labels of active pharmaceutical ingredient (Product Code), and quantities in an excel table. For example:
| Import Date | Product Code | Quantity |
|---|---|---|
| 14/09/2018 | 1 | 300 |
| 18/06/2019 | 1 | 9400 |
| 18/06/2019 | 1 | 5430 |
| 05/06/2019 | 2 | 7000 |
| 17/09/2018 | 3 | 2300 |
First of all i need to merge the same dated and same labelled entries, for example, there is only one importation on 18/06/2019 for product labelled as "1". Also i need to convert the data frame to time series, sorted by dates and with 'Product Code' as a character and 'Quantity' as numeric. When i try with the following code, the result is the following:
# Pacman, version 0.4.1 is used to organize the packages used in R.
library(pacman)
p_load(readxl, readr, ggplot2, forecast, fpp2, tidyverse, TTR, dplyr, zoo, xts)
dat <- read_xlsx("C://Users/oozgen/Desktop/Albania Statistical Analysis/labelleddata.xlsx", col_names=T)
# We need to format the 'Import Date' column as Date format (Year/Month), and sort by Date
orderdates <- as.Date(dat$`Import Date`)
# Since labeling is done numerically, we need to convert the 'Product Code' column from numeric format to character format in R.
dat <- transform(dat, 'Product Code' = as.character(dat$`Product Code`), 'Import Date' = orderdates)
dat_ts <- as.xts(x = dat[, -1], order.by = dat$Import.Date)
head(dat_ts)
| Product.Code | Quantity | |
|---|---|---|
| 2018-01-04 | "784" | " 29976" |
| 2018-01-04 | "1149" | " 200" |
| 2018-01-05 | "306" | " 1000" |
| 2018-01-05 | "713" | " 50" |
| 2018-01-05 | "744" | " 5040" |
| 2018-01-05 | "744" | " 5040" |
Both 'Product Code' and 'Quantity' are in character format. Also you might have noticed, it will be difficult to forecast for separate products on a single table. Do i have to separate all products to different tables and forecast them separately?
You can access to a sample data set from this link*.
Thank you,
Best Regards.
CodePudding user response:
Using DF shown in the Note at the end, convert the columns that should be numeric to numeric, use read.zoo splitting on Product Code and aggregating using sum and convert to xts. At the end optionally replace the NA cells with 0.
library(xts) # also pulls in zoo
x <- DF |>
type.convert(as.is = TRUE) |>
read.zoo(format = "%d/%m/%Y", split = "Product Code", aggregate = sum) |>
as.xts()
x[is.na(x)] <- 0
giving:
> x
1 2 3
2018-09-14 300 0 0
2018-09-17 0 0 2300
2019-06-05 0 7000 0
2019-06-18 14830 0 0
Note
DF <- structure(list(`Import Date` = c("14/09/2018", "18/06/2019",
"18/06/2019", "05/06/2019", "17/09/2018"), `Product Code` = c("1",
"1", "1", "2", "3"), Quantity = c("300", "9400", "5430", "7000",
"2300")), row.names = c(NA, -5L), class = "data.frame")
CodePudding user response:
The simplest way to do this would be with the fable package, which is designed to handle multiple time series at once, and integrates with the tidyverse collection of packages. Here is an example using your sample data.
library(fpp3)
#> ── Attaching packages ─────────────────────────────────────── fpp3 0.4.0.9000 ──
#> ✓ tibble 3.1.4 ✓ tsibble 1.0.1
#> ✓ dplyr 1.0.7 ✓ tsibbledata 0.3.0.9000
#> ✓ tidyr 1.1.3 ✓ feasts 0.2.2.9000
#> ✓ lubridate 1.7.10 ✓ fable 0.3.1.9000
#> ✓ ggplot2 3.3.5
#> ── Conflicts ───────────────────────────────────────────────── fpp3_conflicts ──
#> x lubridate::date() masks base::date()
#> x dplyr::filter() masks stats::filter()
#> x tsibble::intersect() masks base::intersect()
#> x tsibble::interval() masks lubridate::interval()
#> x dplyr::lag() masks stats::lag()
#> x tsibble::setdiff() masks base::setdiff()
#> x tsibble::union() masks base::union()
# Read data and clean up
dat <- readr::read_csv(
"~/Downloads/albaniaingredient_result.xlsx - Sheet1.csv",
name_repair = janitor::make_clean_names
) %>%
mutate(
# Interpret dates
import_date = dmy(import_date),
# Format product codes as character strings with leading zeros
product_code = sprintf("d",product_code)
) %>%
# Make date/code combinations unique
group_by(import_date, product_code) %>%
summarise(quantity = sum(quantity), .groups="drop") %>%
# Create tsibble
as_tsibble(index=import_date, key=product_code) %>%
# Fill missing dates with zeros
fill_gaps(quantity = 0)
#> Rows: 3086 Columns: 3
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> chr (1): import_date
#> dbl (2): product_code, quantity
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
# Produce daily forecasts
fc <- dat %>%
model(croston = CROSTON(quantity)) %>%
forecast(h = "14 days")
#> Warning: 16 errors (1 unique) encountered for croston
#> [16] At least two non-zero values are required to use Croston's method.
# forecasts for product 014
fc %>%
filter(product_code == "014")
#> # A fable: 14 x 5 [1D]
#> # Key: product_code, .model [1]
#> product_code .model import_date quantity .mean
#> <chr> <chr> <date> <dist> <dbl>
#> 1 014 croston 2020-12-04 4773.584 4774.
#> 2 014 croston 2020-12-05 4773.584 4774.
#> 3 014 croston 2020-12-06 4773.584 4774.
#> 4 014 croston 2020-12-07 4773.584 4774.
#> 5 014 croston 2020-12-08 4773.584 4774.
#> 6 014 croston 2020-12-09 4773.584 4774.
#> 7 014 croston 2020-12-10 4773.584 4774.
#> 8 014 croston 2020-12-11 4773.584 4774.
#> 9 014 croston 2020-12-12 4773.584 4774.
#> 10 014 croston 2020-12-13 4773.584 4774.
#> 11 014 croston 2020-12-14 4773.584 4774.
#> 12 014 croston 2020-12-15 4773.584 4774.
#> 13 014 croston 2020-12-16 4773.584 4774.
#> 14 014 croston 2020-12-17 4773.584 4774.
fc %>%
filter(product_code == "014") %>%
autoplot(filter(dat, year(import_date) >= 2020))
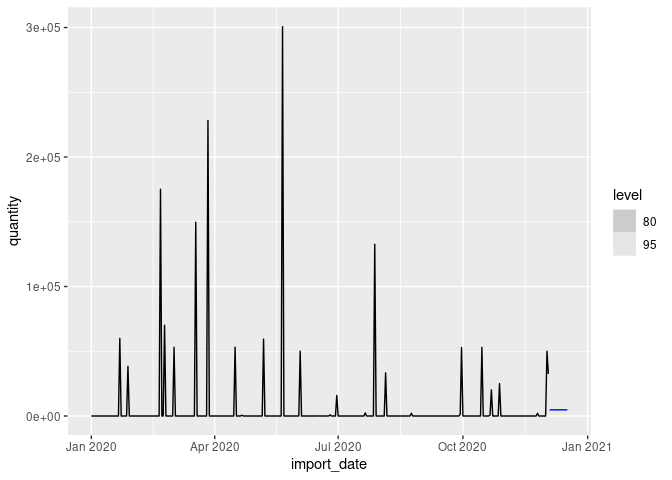
Created on 2021-09-23 by the reprex package (v2.0.1)
I've used Croston's method because your data has far too many zeros for most methods. If you aggregated the data to weekly or monthly, you would then be able to use more reliable methods.
A textbook discussing the fable package is freely available online at OTexts.com/fpp3