i have an input file like below with multpile rows of dictionaries where the key columns remains same:
{'TABSCHEMA': 'OP', 'TABNAME': 'T1', 'COLNO': 9, 'COLNAME': 'ACD'}
{'TABSCHEMA': 'OPE', 'TABNAME': 'T1', 'COLNO': 8, 'COLNAME': 'AC_CD'}
{'TABSCHEMA': 'OPEW', 'TABNAME': 'T2', 'COLNO': 7, 'COLNAME': 'AC_ID'}
and i want to convert it to data frame like below:
Expected O/p:
TABSCHEMA TABNAME COLNO COLNAME
0 OP T1 9 ACD
1 OPE T1 8 ACC_D
2 OPEW T2 7 AC_ID
SQL used:
import pandas as pd
def compare(File1,File2):
with open(File1,'r') as f:
d=set(f.readlines())
with open(File2,'r') as f:
e=set(f.readlines())
with open('pandastry1.txt','w') as f:
for line in list(e-d):
dict_count = len(line)
print(dict_count)
df = pd.DataFrame(line[0], index=[0])
print(df)
compare('OPd.txt','OPER.txt')
Seems like some issue with query,. Can help?
CodePudding user response:
please check the following solution.

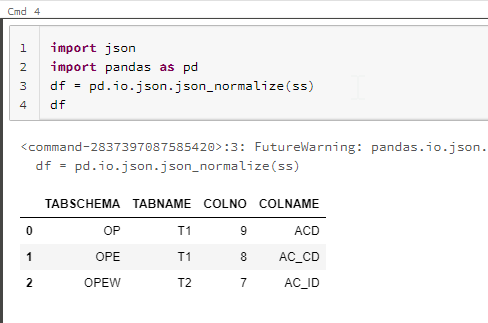
Hope this is what you looking for.
ss = [{'TABSCHEMA': 'OP', 'TABNAME': 'T1', 'COLNO': 9, 'COLNAME': 'ACD'},
{'TABSCHEMA': 'OPE', 'TABNAME': 'T1', 'COLNO': 8, 'COLNAME': 'AC_CD'},
{'TABSCHEMA': 'OPEW', 'TABNAME': 'T2', 'COLNO': 7, 'COLNAME': 'AC_ID'}]
import json
import pandas as pd
df = pd.io.json.json_normalize(ss)
df.to_excel(‘excel_filename.xlsx’)
CodePudding user response:
You could try the following:
...
df = pd.DataFrame(eval(line))
...
instead of df = pd.DataFrame(line[0], index=[0]).
For reading the full file into a dataframe you could do:
with open("input.txt", "r") as file:
df = pd.DataFrame.from_records(eval(line) for line in file.readlines())
(Replace input.txt with your file name.)
Are you sure your file looks like you've shown and it isn't a JSON-file?