I want to "duplicate" the rows the same number of times that the difference between two dates in the df. I have this dataframe:

So I need to explode the number of rows of the df to get this:
CodePudding user response:
Get all dates between D1 and D2 using sequence and then explode the dates:
df = ...
df.withColumn("D1", F.explode(F.expr("sequence(D1,D2)"))) \
.drop("D2").show(truncate=False)
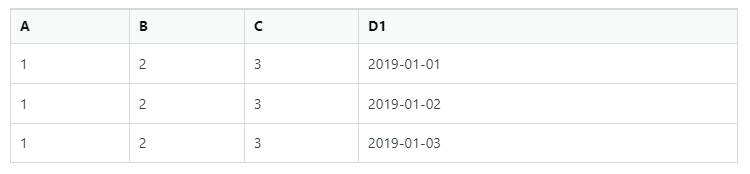
Output:
--- --- --- ----------
|A |B |C |D1 |
--- --- --- ----------
|1 |2 |3 |2019-01-01|
|1 |2 |3 |2019-01-02|
|1 |2 |3 |2019-01-03|
--- --- --- ----------