I have a table in PostgreSQL where I want to select any new "ticker" values, that weren't in the table the previous "trade_date".
The following query takes 1 minute to run and the table contains about 56k rows:
SELECT DISTINCT a.trade_date, a.ticker, a.company_name
FROM t_ark_holdings a
WHERE a.ticker NOT IN (
SELECT b.ticker FROM t_ark_holdings b WHERE b.trade_date <a.trade_date
)
ORDER BY a.trade_date DESC, a.ticker, a.company_name
My table structure is as follow:
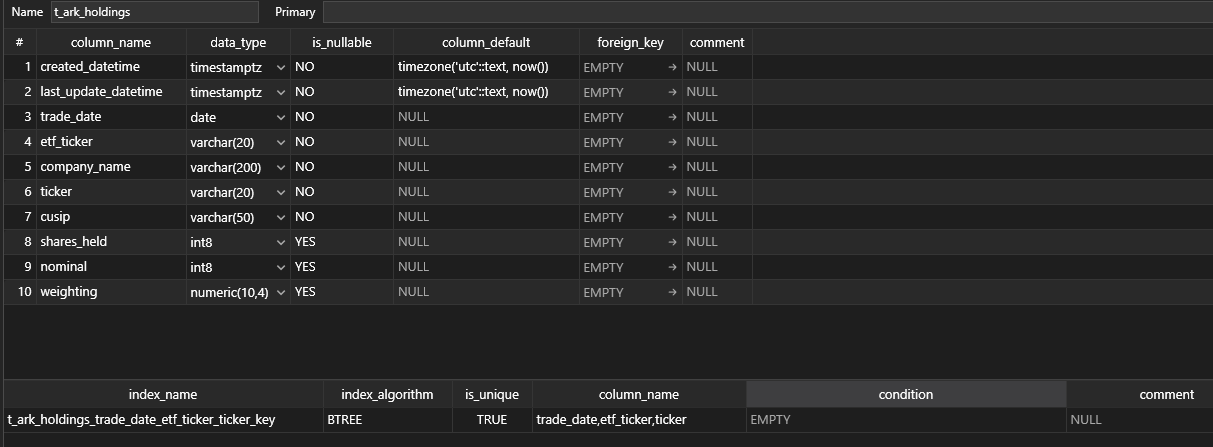
I was wondering a few things:
- Is this the efficient way to write the SQL query
- Should I add indexes on "trade_date" and "ticker" to the table structure
- Would it help to switch to pandas as the table will grow in size with time Thanks
EDIT:
Adding the results wanted:
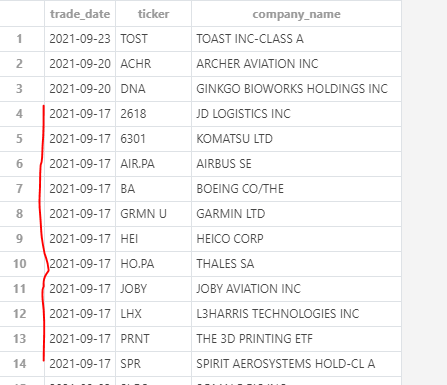
So for instance, on the 9/17/21, there were a few tickers (highlited in red) that weren't in the table on the previous days
CodePudding user response:
If you want the first row for each ticker/company_name, use distinct on:
select distinct on (a.ticker, a.company_name) a.*
from t_ark_holdings a
order by a.ticker, a.company_name, a.trade_date;
With an index on (ticker, company_name, trade_date) this should be something like blindingly fast.
CodePudding user response:
You are selecting all results in the subquery, which generates lots of data into memory in your RDBMS that your value is compared to. You instead should use a LEFT JOIN with a WHERE clause, like this:
SELECT a.trade_date, a.ticker, a.company_name
FROM t_ark_holdings a
LEFT JOIN t_ark_holdings b
ON a.ticker = b.ticker and b.trade_date < a.trade_date
WHERE b.ticker IS NULL
ORDER BY a.trade_date DESC, a.ticker, a.company_name
This query asks hypothetically for any b record that has the same ticker a has, but with an earlier date and the WHERE clause checks whether it exists and only includes the result if it doesn't. Note that I removed the DISTINCT keyword, assuming that you will not have multiple ticker values in the newest findings with the same date. If the query is still slow, then you might need an index. Try creating the index and compare performance vs. the performance without the index.
Another point to make is that you speak about previous trade date. If that's a known date or date range, then you could further your criteria with checking whether b is in that date/date range.