I'm trying to tabulate a text file with following format. It like blocks of data that appears several times. First 5 fields normally appears once in each block of info and in output I'd like to have them fill down (values in green).
SOME TEXT
SOME TEXT
SOME TEXT
GSHSH = 0 OK:SUCCESS
ABC = 1
TDE = 0
TNLH = WL_CS
TKKJW = ZZR
MBTYIE = PRM
MHGT = 165
MRLL = CTM
TTDDX = 0
ZDTR = FALSE
UEEM = FALSE
KQTY = FALSE
MHGT = 211
MRLL = CTM
TTDDX = 0
ZDTR = FALSE
UEEM = FALSE
KQTY = FALSE
MHGT = 32
MRLL = CTM
TTDDX = 0
ZDTR = FALSE
UEEM = FALSE
KQTY = FALSE
SOME TEXT
SOME TEXT
SOME TEXT
GSHSH = 23 OK:SUCCESS
ABC = 1
TDE = 0
TNLH = WL_PS
KKJW = ZZZN
MBTYIE = PRM
MHGT = 9254
MRLL = PRM
ZDTR = FALSE
UEEM = FALSE
KQTY = FALSE
SOME TEXT
SOME TEXT
SOME TEXT
GSHSH = 0 OK:SUCCESS
ABC = 1
TDE = 1
TNLH = RTC_RMN
TKKJW = ZZR
BTYIE = RTC
MHGT = 1150
MRLL = PRM
ZDTR = FALSE
UEEM = FALSE
KQTY = FALSE
MHGT = 41
MRLL = CTM
TTDDX = 0
ZDTR = FALSE
UEEM = FALSE
KQTY = FALSE
SOME TEXT
SOME TEXT
SOME TEXT
GSHSH = 1 OK:SUCCESS
My desired output would be like this:
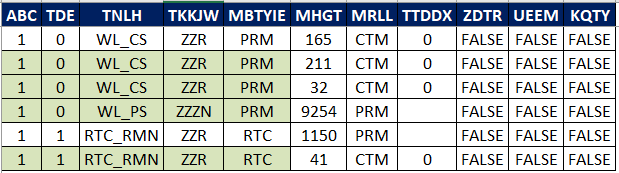
My current code is like below, I'm able to read the data and store values in a defaultdict. After that I'm trying to convert to pandas data frame but I get error. And I'm stuck in how to organize the values to be printed in correct column. Thanks for any help
import re
from collections import defaultdict
from tabulate import tabulate
import pandas as pd
file = 'file.txt'
f=open(file,"r").read().splitlines()
lst=[]
for line in f:
if re.match(r'[ \t]', line):
lst.append(line.replace(' ', '').split('='))
print(lst)
d = defaultdict(list)
for k, v in lst:
d[k].append(v)
>>> d
defaultdict(<class 'list'>, {'ABC': ['1', '1', '1'], 'TDE': ['0', '0', '1'], 'TNLH': ['WL_CS',
'WL_PS', 'RTC_RMN'], 'TKKJW': ['ZZR', 'ZZR'], 'MBTYIE': ['PRM', 'PRM'], 'MHGT': ['165', '211',
'32', '9254', '1150', '41'], 'MRLL': ['CTM', 'CTM', 'CTM', 'PRM', 'PRM', 'CTM'], 'TTDDX':
['0', '0', '0', '0'], 'ZDTR': ['FALSE', 'FALSE', 'FALSE', 'FALSE', 'FALSE', 'FALSE'], 'UEEM':
['FALSE', 'FALSE', 'FALSE', 'FALSE', 'FALSE', 'FALSE'], 'KQTY': ['FALSE', 'FALSE', 'FALSE',
'FALSE', 'FALSE', 'FALSE'], 'KKJW': ['ZZZN'], 'BTYIE': ['RTC']})
df = pd.DataFrame.from_dict(d)
>> ValueError: arrays must all be same length
CodePudding user response:
Try:
file = 'file.txt'
f=open(file,"r").read().splitlines()
lst=[]
data = {}
dfs = []
group = 1
for line in f:
if line.endswith('SUCCESS'):
print(f'============== {line} ================')
if data:
df = pd.DataFrame.from_dict(data)
df = pd.pivot(data=df, columns=['col'], values=['val'], index=['group']).reset_index(drop=True)
df.columns = df.columns.droplevel()
df.fillna(method='ffill', inplace=True)
dfs.append(df)
data = []
group = 1
else:
if re.match(r'[ \t]', line):
split_data = line.replace(' ', '').split('=')
data.append({'group': group, 'col': split_data[0], 'val': split_data[1]})
if not line.strip():
group =1
cols_order = ['ABC', 'TDE', 'TNLH', 'TKKJW', 'MBTYIE', 'MHGT', 'MRLL', 'TTDDX', 'ZDTR', 'UEEM', 'KQTY']
fina_df = pd.concat(dfs, ignore_index=True)
fina_df['TKKJW'].fillna(fina_df['KKJW'], inplace=True)
fina_df['MBTYIE'].fillna(fina_df['BTYIE'], inplace=True)
fina_df = fina_df[cols_order]
OUTPUT:
col ABC TDE TNLH TKKJW MBTYIE MHGT MRLL TTDDX ZDTR UEEM KQTY
0 1 0 WL_CS ZZR PRM 165 CTM 0 FALSE FALSE FALSE
1 1 0 WL_CS ZZR PRM 211 CTM 0 FALSE FALSE FALSE
2 1 0 WL_CS ZZR PRM 32 CTM 0 FALSE FALSE FALSE
3 1 0 WL_PS ZZZN PRM 9254 PRM NaN FALSE FALSE FALSE
4 1 1 RTC_RMN ZZR RTC 1150 PRM NaN FALSE FALSE FALSE
5 1 1 RTC_RMN ZZR RTC 41 CTM 0 FALSE FALSE FALSE