I have two Excel files 2A.xlsx and Purchase Register.xlsx
2A.xlsx looks like this:
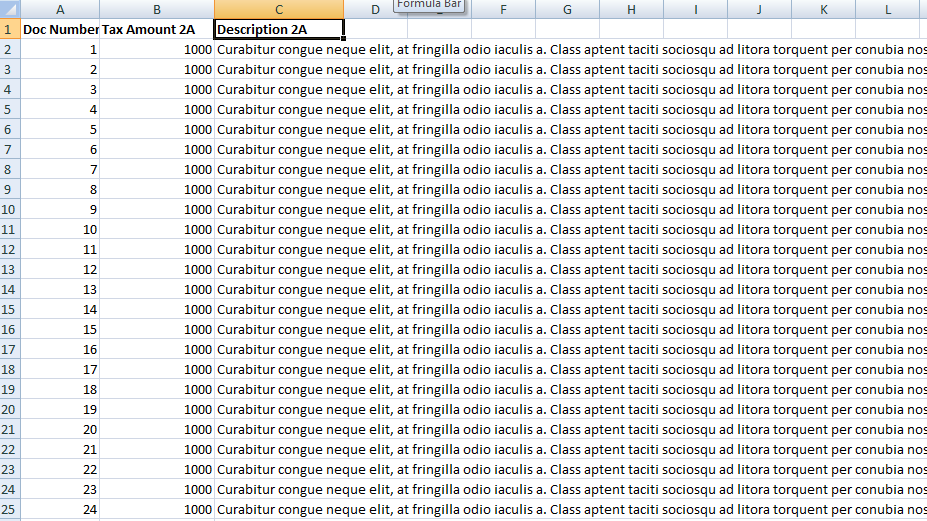
Purchase Register.xlsx look like this::
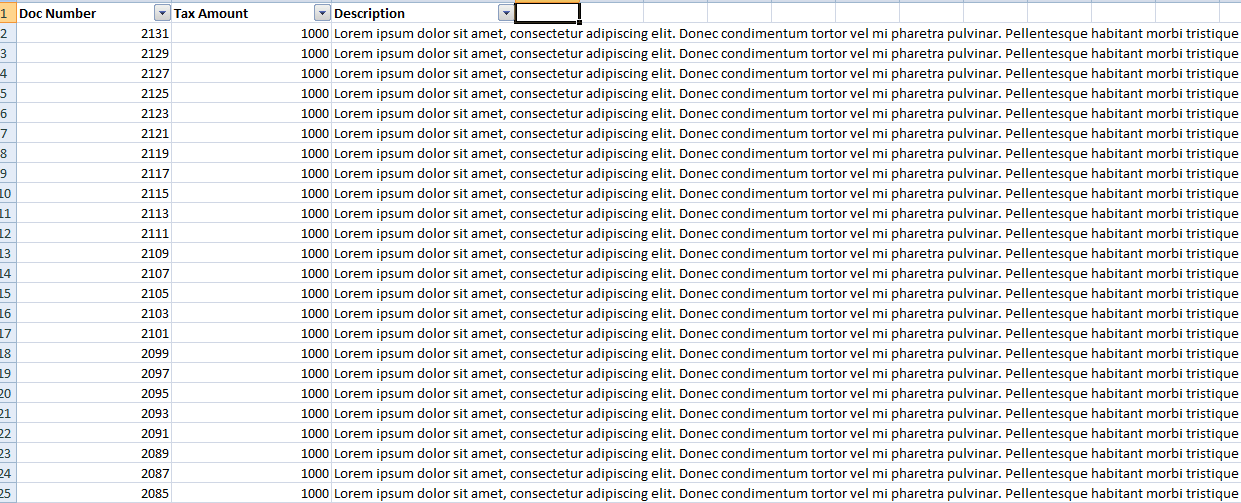
I want to have my filtered output (in new Excel file) in format like this: [ Sample filtered data][3] [3]: https://i.stack.imgur.com/1Iuhc.png
Here "Exact" are the doc numbers which have same tax amount
"Mismatch" means those doc numbers which have different tax amount
"Addition in 2A" means that those doc numbers which doesn't have any information in their corresponding Purchase Register (PR) file
"Addition in PR" means that those doc numbers which doesn't have any information in their corresponding 2A file
How can I do this in Python? I was using pandas library for it but was unsuccessful, really struggling with this problem for a week. Does anyone know how can I do this?
CodePudding user response:
Using Pandas (as you suggested), you can do an outer-join style merge of the two tables, keyed on the document ID. This will give you a dataframe where each row contains all of the information you need.
import pandas as pd
df1 = pd.DataFrame([[1, 1, "Desc 1"], [2, 2, "Desc 1"], [3, 3, "Desc 3"]],
columns=["Doc Number", "Tax Amount 2A", "Description 2A"])
df2 = pd.DataFrame([[1, 1, "Desc 4"], [2, 20, "Desc 5"], [4, 4, "Desc 6"]],
columns=["Doc Number", "Tax Amount PR", "Description PR"])
combined = pd.merge(df1, df2, how="outer", on="Doc Number")
combined.head()
Doc Number Tax Amount 2A Description 2A Tax Amount PR Description PR
1 1.0 Desc 1 1.0 Desc 4
2 2.0 Desc 1 20.0 Desc 5
3 3.0 Desc 3 NaN NaN
4 NaN NaN 4.0 Desc 6
From there, you can apply a function to each row and do the comparison of the values to produce the appropriate rule.
def case_code(row):
if row["Tax Amount 2A"] == row["Tax Amount PR"]:
return "exact"
elif pd.isna(row["Tax Amount 2A"]):
return "Addition in PR"
elif pd.isna(row["Tax Amount PR"]):
return "Addition in 2A"
elif row["Tax Amount 2A"] != row["Tax Amount PR"]:
return "mismatch"
codes = combined.apply(case_code, axis="columns")
codes
Doc Number
1 exact
2 mismatch
3 Addition in 2A
4 Addition in PR
dtype: object
The key part is to apply to each row (with axis="columns") instead of the default behavior of applying to each column.
The new codes can be added to the combined dataframe. (The 2nd line just makes the new codes the first column to match your example by re-arranging the columns and not strictly-speaking required.)
answer = combined.assign(**{"Match type": codes})
answer[["Match type"] [*combined.columns]]
Match type Doc Number Tax Amount 2A Description 2A ...
exact 1 1.0 Desc 1 ...
mismatch 2 2.0 Desc 2 ...
Addition in 2A 3 3.0 Desc 3 ...
Addition in PR 4 NaN NaN ...
(Final table isn't showing all the columns because I couldn't get it to format correctly.)