I have a dataframe like as shown below
df = pd.DataFrame({'Credit_History':['Yes','ABC','DEF', 'JKL'],
'Loan_Status':['T1','T2',np.nan,np.nan],
'subject_status':['DUMMA','CHUMMA',np.nan,np.nan],
'test_status':['test',np.nan,np.nan,np.nan]})
My objective is to fill the missing values with the corresponding credit_history value across all rows and columns
I tried the below but it doesn't work
cols = ['Loan_Status','subject_status','test_status']
df[cols] = df[cols].fillna(df['Credit_History'])
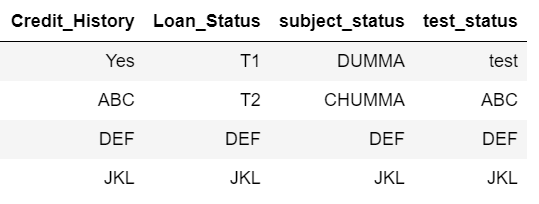
I expect my output to be like as shown below. Basically, whichever row is missing, it should pick the corresponding value from credit_history column
CodePudding user response:
Use DataFrame.apply, so is used Series.fillna:
cols = ['Loan_Status','subject_status','test_status']
df[cols] = df[cols].apply(lambda x: x.fillna(df['Credit_History']))
print (df)
Credit_History Loan_Status subject_status test_status
0 Yes T1 DUMMA test
1 ABC T2 CHUMMA ABC
2 DEF DEF DEF DEF
3 JKL JKL JKL JKL
Or with transpose:
cols = ['Loan_Status','subject_status','test_status']
df[cols] = df[cols].T.fillna(df['Credit_History']).T
print (df)
Credit_History Loan_Status subject_status test_status
0 Yes T1 DUMMA test
1 ABC T2 CHUMMA ABC
2 DEF DEF DEF DEF
3 JKL JKL JKL JKL