I'm performing feature selection with Catbost. This the training code:
# Parameter grid
params = {
'auto_class_weights': 'Balanced',
'boosting_type': 'Ordered',
'thread_count': -1,
'random_seed': 24,
'loss_function': 'MultiClass',
'eval_metric': 'TotalF1:average=Macro',
'verbose': 0,
'classes_count': 3,
'num_boost_round':500,
'early_stopping_rounds': EARLY_STOPPING_ROUNDS
}
# Datasets
train_pool = Pool(train, y_train)
test_pool = Pool(test, y_test)
# Model Constructor
ctb_model = ctb.CatBoostClassifier(**params)
# Run feature selection
summary = ctb_model.select_features(
train_pool,
eval_set=test_pool,
features_for_select='0-{0}'.format(train.shape[1]-1),
num_features_to_select=10,
steps=1,
algorithm=EFeaturesSelectionAlgorithm.RecursiveByShapValues,
shap_calc_type=EShapCalcType.Exact,
train_final_model=True,
logging_level='Silent',
plot=True
)
After the run has ended, the following plot is displayed:
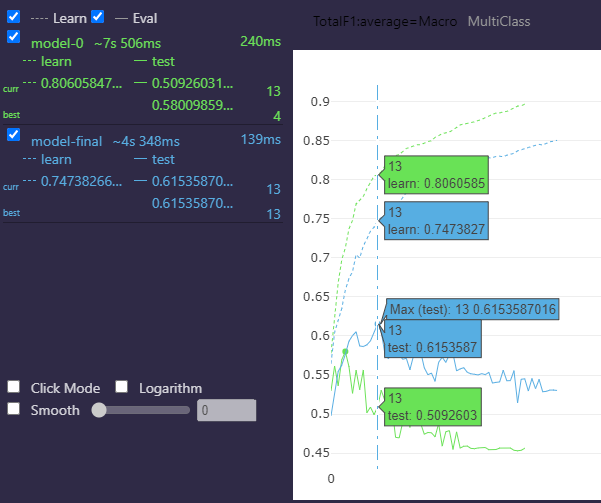
It is clear that according to the plot the evaluation metric is TotalF1 with macro average, and the best iteration of the model achieved 0.6153 as the best score for this metric. According to the documentation, when the train_final_model argument is set to True, a model is finally fitted using the selected features that gave the best score for the specified evaluation metric during the feature selection process, so one would expect to get the same results when using the fitted model to make predictions and evaluate it. However, this is not the case.
When running:
from sklearn.metrics import f1_score
predictions = ctb_model.predict(test[summary['selected_features_names']], prediction_type='Class')
f1_score(y_test, predictions, average='macro')
The result i'm getting is:
0.41210319323424227
The difference is huge, and i can't figure out what is causing this difference and how can i fix it.
Can someone please help me solving this issue?
Thank you very much in advance.
CodePudding user response:
The solution to this question can be found at: CatBoost precision imbalanced classes
After setting the parameter sample_weights of the sklearn's f1_score(), i got the same F1 score than Catboost was throwing.
Hope it helps somebody else.