I have the following data frame called studenti:
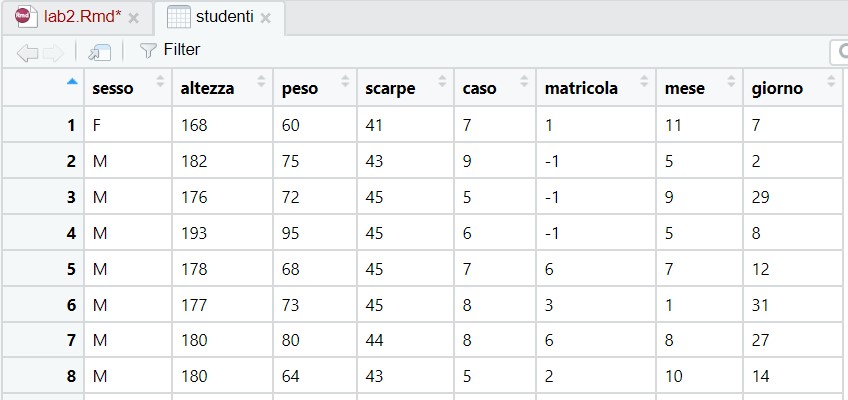
When I tried to run the following code:
maschi = data.frame()
indice = 0
for (i in seq_along(studenti$sesso)) {
if (studenti$sesso[i] == "M") {
indice = indice 1
maschi[indice,] <- studenti[i,]
}
}
the following error appeared "Error in if () { : missing value where TRUE/FALSE needed".
My goal is to copy in the data frame maschi only the rows of the data frame studenti such that sesso=M.
EDIT

EDIT: dput output
structure(list(sesso = c("F", "M", "M", "M", "M"), altezza = c(168,
182, 176, 193, 178), peso = c(60, 75, 72, 95, 68), scarpe = c(41,
43, 45, 45, 45), caso = c(7, 9, 5, 6, 7), matricola = c(1, -1,
-1, -1, 6), mese = c(11, 5, 9, 5, 7), giorno = c(7, 2, 29, 8,
12)), row.names = c(NA, 5L), class = "data.frame")
CodePudding user response:
It may be easier to use subset
maschi <- subset(studenti, sesso == "M")
or filter from dplyr
library(dplyr)
studenti %>%
filter(sesso == "M")
The for loop can be done with rbind
maschi <- studenti[0,]
for(i in seq_len(nrow(studenti))) {
if(studenti$sesso[i] == "M" & !is.na(studenti$sesso[i])) {
maschi <- rbind(maschi, studenti[i,])
}
}
Also, in the OP's code, we just need
maschi <- studenti[0,]
indice = 0
for (i in seq_along(studenti$sesso)) {
if (studenti$sesso[i] == "M" & !is.na(studenti$sesso[i])) {
indice = indice 1
maschi[indice,] <- studenti[i,]
}
}
-output
> maschi
sesso altezza
2 M 182
3 M 176
4 M 193
-Update using the OP's update data
> maschi
sesso altezza peso scarpe caso matricola mese giorno
2 M 182 75 43 9 -1 5 2
3 M 176 72 45 5 -1 9 29
4 M 193 95 45 6 -1 5 8
5 M 178 68 45 7 6 7 12
data
studenti <- data.frame(sesso = c("F", "M", "M", "M"), altezza = c(168, 182, 176, 193))