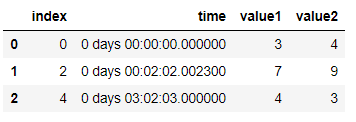
I want to reduce my data. My initial dataframe looks as follows:
| index | time [hh:mm:ss] | value1 | value2 |
|---|---|---|---|
| 0 | 0 days 00:00:00.000000 | 3 | 4 |
| 1 | 0 days 00:00:04.000000 | 5 | 2 |
| 2 | 0 days 00:02:02.002300 | 7 | 9 |
| 3 | 0 days 00:02:03.000000 | 9 | 7 |
| 4 | 0 days 03:02:03.000000 | 4 | 3 |
Now I want to reduce my data in order to only keep the cells of every new minute (respectively also new hour and days). the other way around: only the first line of a new minute should be kept. all remaining lines of this minute should be dropped. So the resulting table looks as follows:
| index | time | value1 | value2 |
|---|---|---|---|
| 0 | 0 days 00:00:00.000000 | 3 | 4 |
| 2 | 0 days 00:02:02.002300 | 7 | 9 |
| 4 | 0 days 03:02:03.000000 | 4 | 3 |
Any ideas how to approach this?
CodePudding user response:
There is used timedeltas so is possible create TimedeltaIndex and use 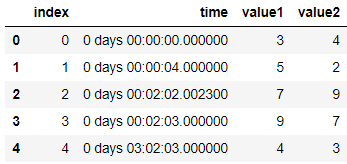
df['time1'] = pd.to_datetime(df['time'].str.slice(7)) df.set_index('time1',inplace=True)
df
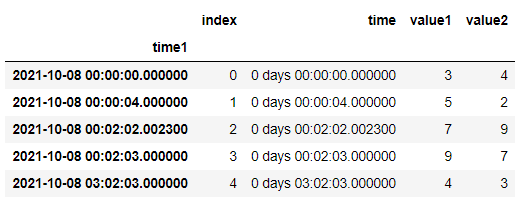
df.groupby([df.index.hour,df.index.minute]).head(1).sort_index().reset_index(drop=True)