I am trying to understand the internal workings of koalas. Every tutorial I have used has presented me with three concepts
- Spark dataframe
- Internal frame
- koalas dataframe
According to my understanding, the spark dataframe is the typical distributed spark dataframe. Now, this spark dataframe needs to be presented as a pandas dataframe to make the concepts more lucid which is where the concept of an internal frame comes in. An internal frame keeps the mappings like spark column names --> pandas column names and information about indices etc.
Let this image assist our understanding:
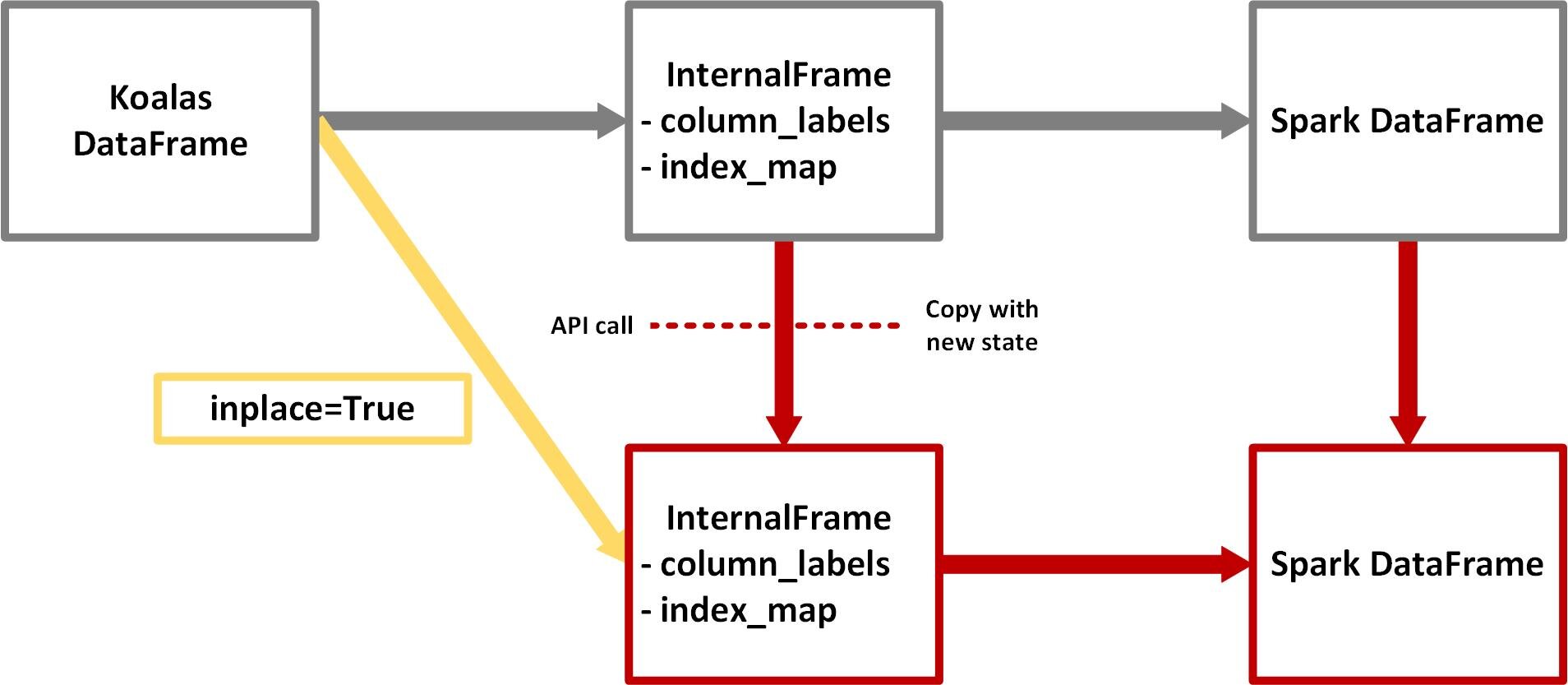
It would seem then like the koalas dataframe is just a logical concept and one can understand it as parsed output of spark dataframe with internal frame providing the parser. It is a layer of abstraction over spark dataframe helpful in making spark dataframe amenable to koalas API (pandas style)
Every API call on a koalas dataframe creates a new internal frame and does or does not create a new spark dataframe.
But, I am also presented with images like this:
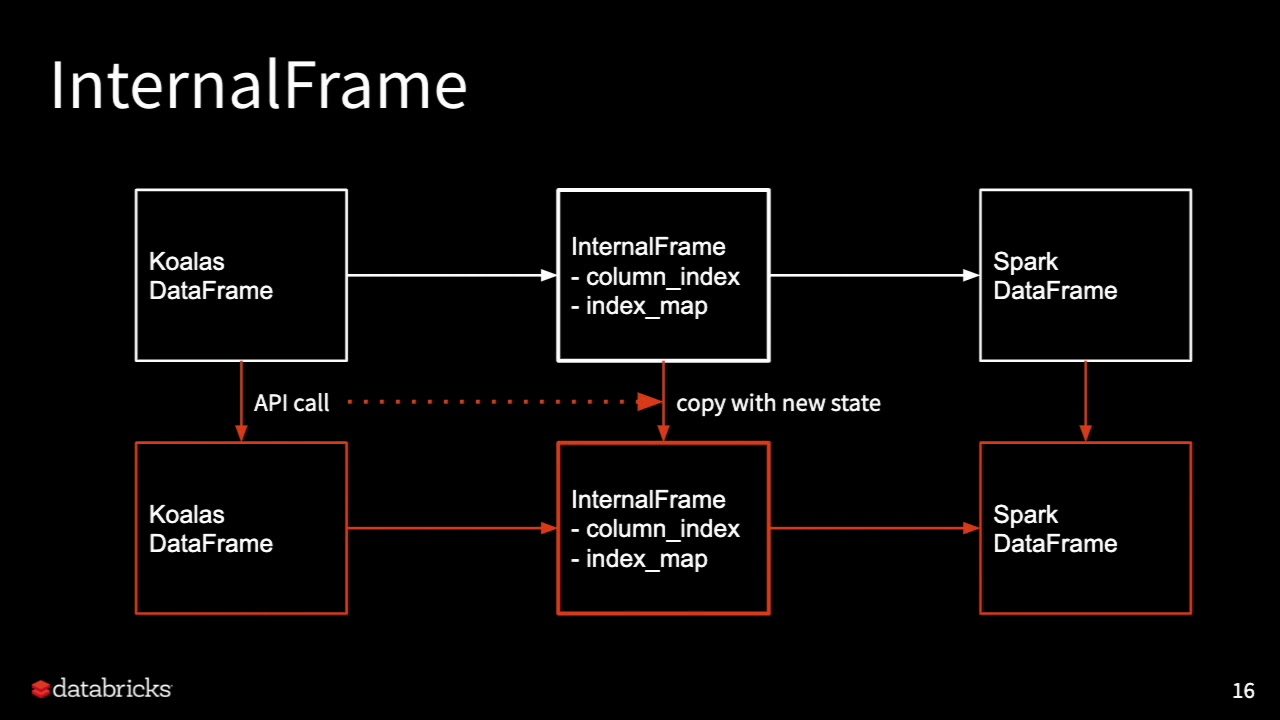
And this is where my confusion lies. What does it mean to create or not create a new koalas dataframe? What exactly is a koalas dataframe? Taking the specific example of the first image, What does it mean to keep the koalas dataframe same while changing the internal frame and spark dataframe when applying operations like kdf.dropna(...,inplace=True)?
CodePudding user response:
Making it way too complex.
The Koalas project makes data scientists more productive when interacting with big data, by implementing the pandas DataFrame API on top of Apache Spark. pandas is the de facto standard (single-node) DataFrame implementation in Python, while Spark is the de facto standard for big data processing. With this package, you can:
Be immediately productive with Spark, with no learning curve, if you are already familiar with pandas. Have a single codebase that works both with pandas (tests, smaller datasets) and with Spark (distributed datasets).
Just an API on top of Spark dataframe.
CodePudding user response:
One of the objectives of Koalas is to provide the Pandas API on top of Spark.
Now, there are some underlying differences b/w Spark DF & Pandas DF and to get rid of these differences Koalas uses the InternalFrame. For example, Pandas DF maintains row order via indexes whereas Spark DF doesn't maintain the order.
So, InternalFrame can be thought of as a bridge b/w Spark and Pandas (if you see it from a user point of view).
As you correctly mentioned: InternalFrame => Spark DF Immutable Metadata.
And, under the hood, Koalas maintains the series of InternalFrames based on the operations performed by the user via Koalas API.
Now, for every operation, it is not necessary to change the underlying Spark DF, e.g. setting a new column as an index then such an operation only needs the metadata to be updated. So, for this Koalas will create a new state of InternalFrame with only the updated metadata.
Similarly, if you are performing a dropna on Koalas DF then under the hood it works in the below manner:
Current state => Koalas DF --> InternalFrame (current Spark DF Metadata)
New state => Same Koalas DF now pointed to --> New InternalFrame (Updated Spark DF after dropna Metadata)
Overall, we can say that Koalas API uses the concept of InternalFrame to provide the Pandas-like API on top of Spark. Thus, with minimal code changes, users can switch from a single node to a cluster.