assuming this is my dataframe
import pandas as pd
import numpy as np
import pandas as pd
df = pd.DataFrame({'30': [-23, 12, -12, 10, -23, 12, -32, 15, -20, 10],
'40': [-30, 20, -21, 15, -33, 22, -40, 25, -22, 12],
'50': [-40, 25, -26, 19, -39, 32, -45, 35, -32, 18],
'60': [-45, 34, -29, 25, -53, 67, -55, 45, -42, 19],
})
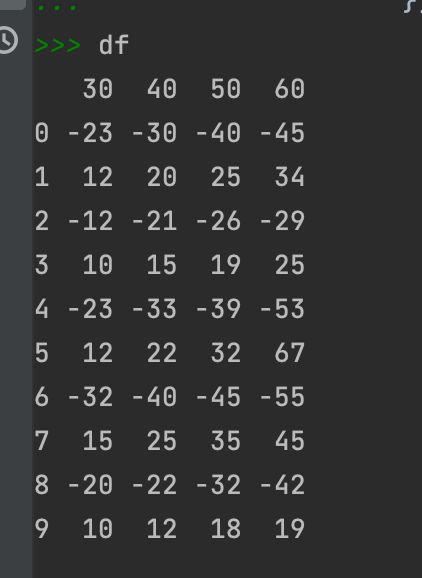
how do I get a column at the end whose values are the list of values from other columns on that row
i.e.
The first row of the new columns will contain [-23,-30,-40,-45], the 2nd row will contain [12,20,25,34] and so on.
CodePudding user response:
Use:
#if need all columns to lists
df['new'] = df.to_numpy().tolist()
#if need specify columns by list
cols = [30,40,50,60]
df['new'] = df[cols].to_numpy().tolist()
print (df)
30 40 50 60 new
0 -23 -30 -40 -45 [-23, -30, -40, -45]
1 12 20 25 34 [12, 20, 25, 34]
2 -12 -21 -26 -29 [-12, -21, -26, -29]
3 10 15 19 25 [10, 15, 19, 25]
4 -23 -33 -39 -53 [-23, -33, -39, -53]
5 12 22 32 67 [12, 22, 32, 67]
6 -32 -40 -45 -55 [-32, -40, -45, -55]
7 15 25 35 45 [15, 25, 35, 45]
8 -20 -22 -32 -42 [-20, -22, -32, -42]
9 10 12 18 19 [10, 12, 18, 19]