I am trying to dump a website (website link is given below in code) and all containers are not loading. In my case, price container is not dumping. See screenshots for more details. How to solve this?
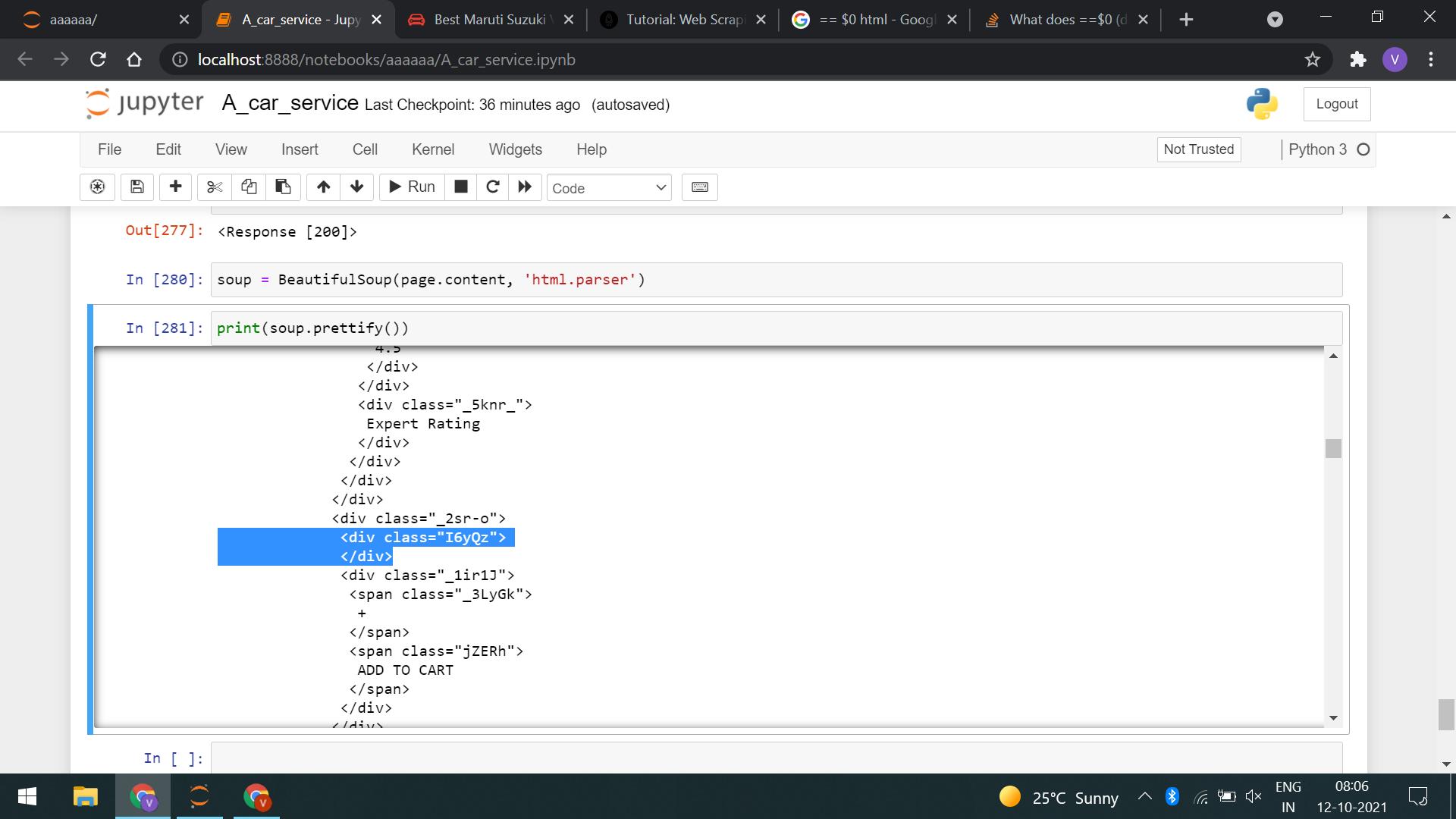
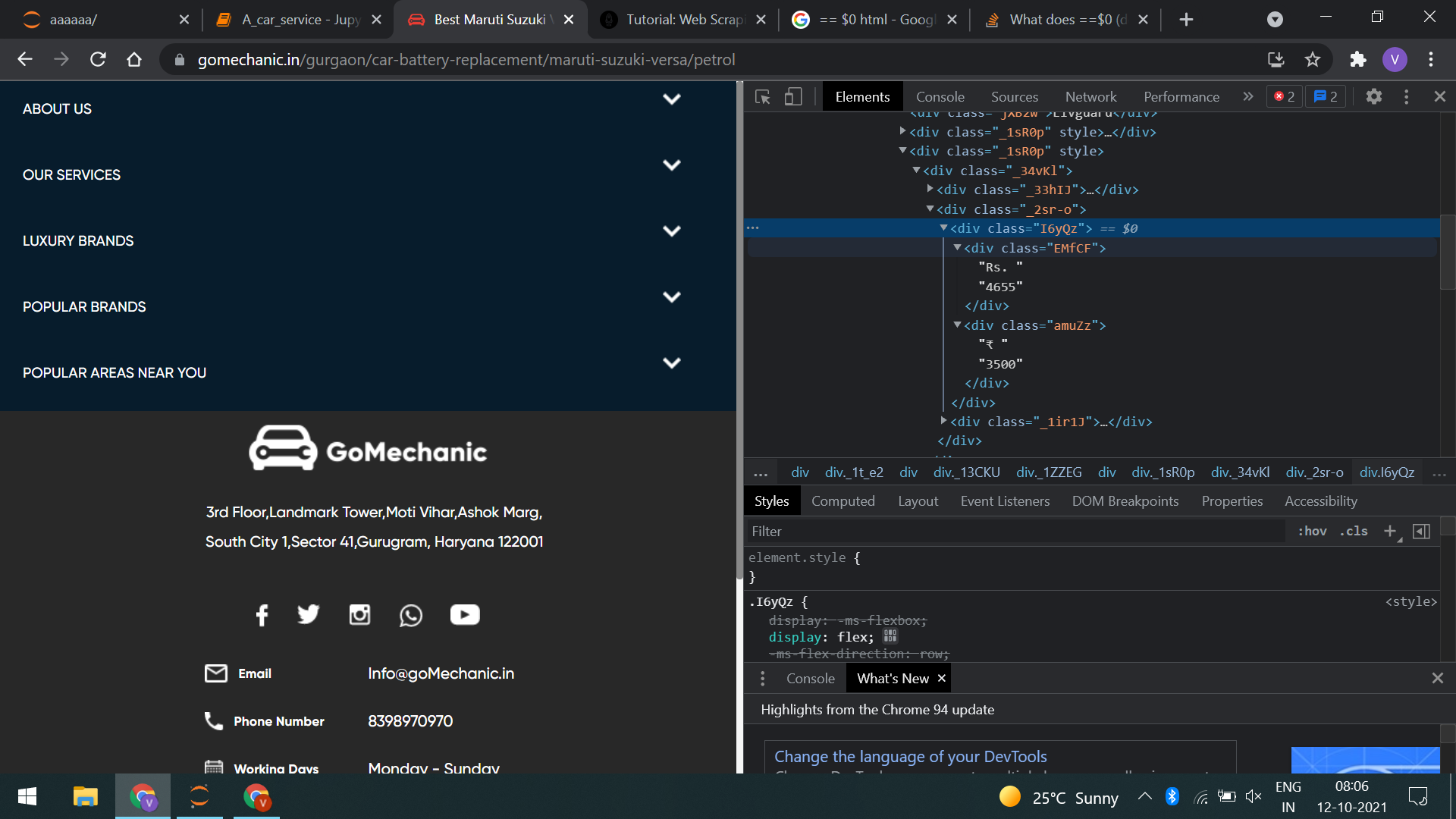
In this case, container inside class "I6yQz" are not loading.
MyCode:
url = "https://gomechanic.in/gurgaon/car-battery-replacement/maruti-suzuki-versa/petrol"
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
print(soup.prettify())
I need the following content shown in screenshot
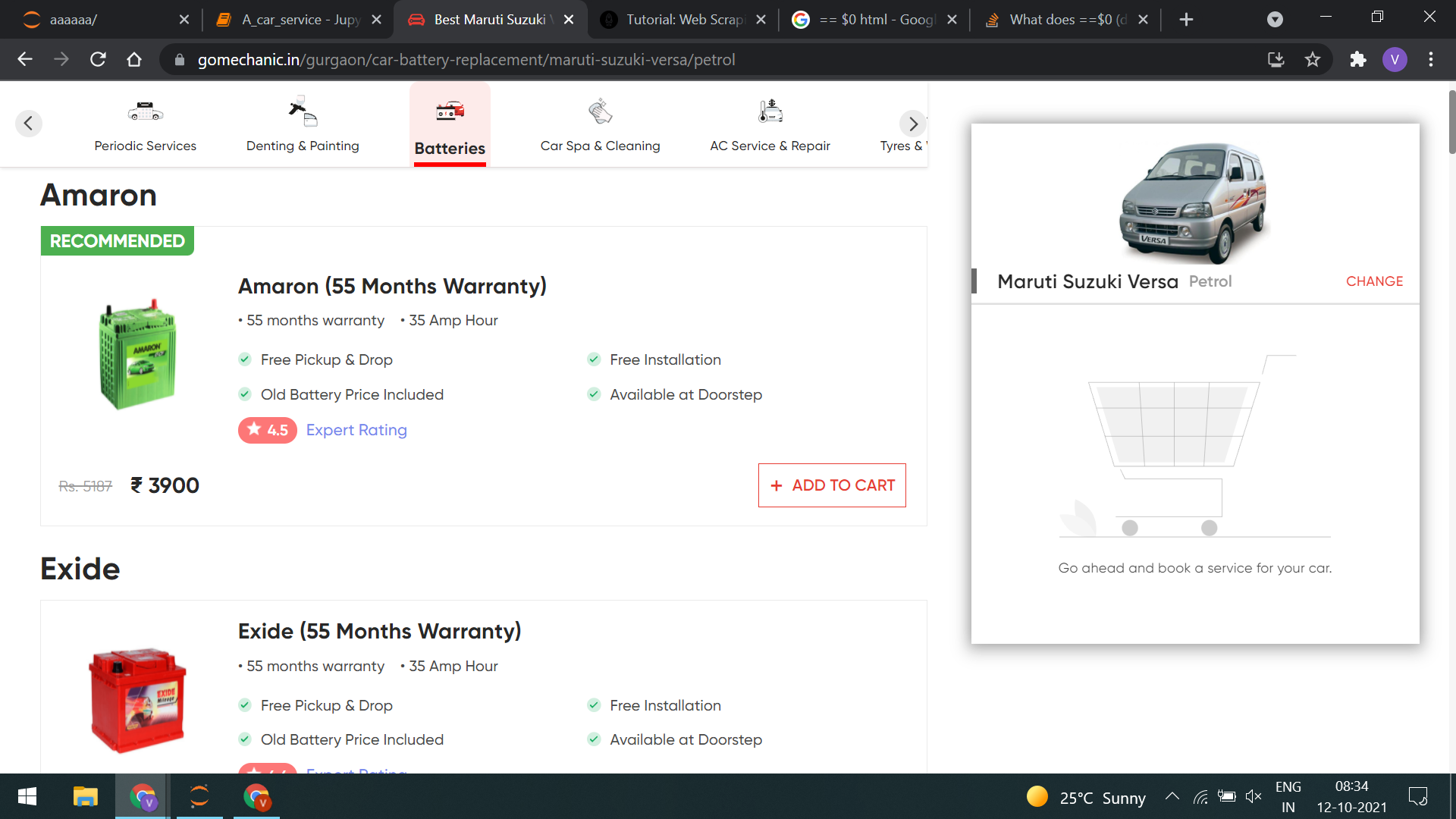
Some thing like this:
data = {'CityName' : 'Gurgaon', 'CarName' : 'Versa-Petrol', 'serviceName' : 'Excide (55 Months Warranty)', 'Price' : '4299', 'ServicesOffered' : '['Free pickup & drop', 'Free Installation', 'Old Battery Price Included', 'Available at Doorstep']}
I have also got the API which is have all the information: 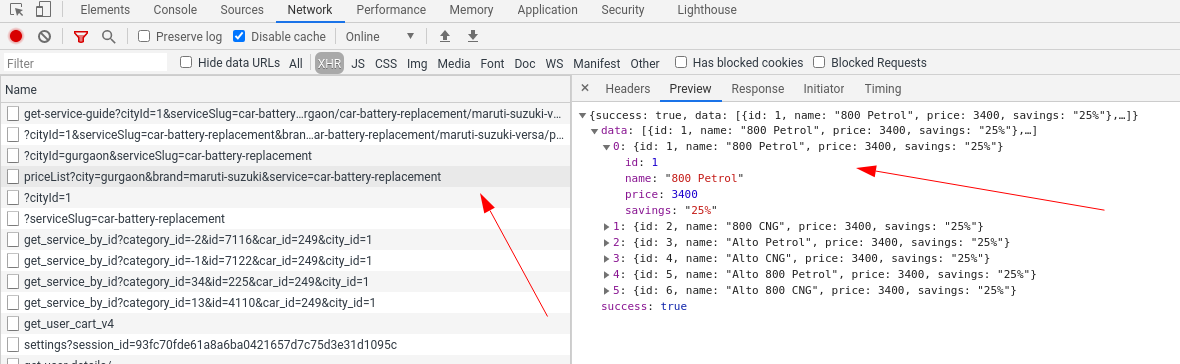
What you have to do is figure out how to replicate this request in your python code:
import requests
headers = {
# this website sues authroization for all requests
'Authorization': 'Bearer eyJhbGciOiJSUzI1NiIsInR5cCI6IkpXVCJ9.eyJqdGkiOiJiNGJjM2NhZjVkMWVhOTlkYzk2YjQzM2NjYzQzMDI0ZTAyM2I0MGM2YjQ5ZjExN2JjMDk5OGY2MWU3ZDI1ZjM2MTU1YWU5ZDIxNjE2ZTc5NSIsInNjb3BlcyI6W10sInN1YiI6IjE2MzM5MzQwNjY5NCIsImV4cCI6MTYzNjUyNjA2Ny4wLCJhdWQiOiIzIiwibmJmIjoxNjMzOTM0MDY3LjAsImlhdCI6MTYzMzkzNDA2Ny4wfQ.QQI_iFpNgONAIp4bfoUbGDtnnYiiViEVsPQEK3ouYLjeyhMkEKyRclazuJ9i-ExQyqukFuqiAn4dw7drGUhRykJY6U67iSnbni0aXzzF9ZTEZrvMmqItHXjrdrxzYCqoKJAf2CYY-4hkO-NXIrTHZEnk-N_jhv30LHuK9A5I1qK8pajt4XIkC7grAn3gaMe3c6rX6Ko-AMZ801TVdACD4qIHb4o73a3vodEMvh4wjIcxRGUBGq4HBgAKxKLCcWaNz-z7XjvYrWhNJNB_iRjZ1YBN97Xk4CWxC0B4sSgA2dVsBWaKGW4ck8wvrHQyFRfFpPHux-6sCMqCC-e4okOhku3AasqPKwvUuJK4oov9tav4YsjfFevKkdsCZ1KmTehtvadoUXAHQcij0UqgMtzNPO-wKYoXwLc8yZGi_mfamAIX0izFOlFiuL26X8XUMP5HkuypUqDa3MLg91f-8oTMWfUjVYYsnjw7lwxKSl7KRKWWhuHwL6iDUjfB23qjEuq2h9JBVkoG71XpA9SrJbunWARYpQ48mc0LlYCXCbGkYIh9pOZba7JGMh7E15YyRla8qhU9pEkgWVYjzgYJaNkhrSNBaIdY56i_qlnTBpC00sqOnHRNVpYMb4gF3PPKalUMMJjbSqzEE2BNTFO5dGxGcz2cKP0smoVi_SK3XcKgPXc',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) QtWebEngine/5.15.2 Chrome/87.0.4280.144 Safari/537.36',
}
url = 'https://gomechanic.in/api/v1/priceList?city=gurgaon&brand=maruti-suzuki&service=car-battery-replacement'
response = requests.get(url, headers=headers)
print(response.json())
Which will result in:
{
"success": true,
"data": [
{
"id": 1,
"name": "800 Petrol",
"price": 3400,
"savings": "25%"
},
{
"id": 2,
"name": "800 CNG",
"price": 3400,
"savings": "25%"
},
{
"id": 3,
"name": "Alto Petrol",
"price": 3400,
"savings": "25%"
},
{
"id": 4,
"name": "Alto CNG",
"price": 3400,
"savings": "25%"
},
{
"id": 5,
"name": "Alto 800 Petrol",
"price": 3400,
"savings": "25%"
},
{
"id": 6,
"name": "Alto 800 CNG",
"price": 3400,
"savings": "25%"
}
]
}
This whole process is called reverse engineering and for a more in-depth introduction you can see my tutorial blog here: https://scrapecrow.com/reverse-engineering-intro.html
As for parameters that are used in these backend API requests - they are most likely in initial html document initial state json object. If you view page source of the html page and ctrl f parameter name like city_id you can see it's hidden deep in some json. You can either extract this whole JSON and parse it or use regular expressions like re.findall('"city_id":(\d )', html)[0] to just get this one value.