I'm running a Speed-up experiment with a Spark job. Unfortunately, I can't seem to limit Spark to truly one core. (I have 128)
I use the following settings to try and achieve this:
os.environ['NUMBEXPR_MAX_THREADS'] = partitions
os.environ['NUMEXPR_NUM_THREADS'] = partitions
spark = SparkSession.builder \
.master("local") \
.config("spark.executor.instances", "1") \
.config("spark.executor.cores", "1") \
.config("spark.sql.shuffle.partitions", "1") \
.config("spark.driver.memory", "50g") \
.getOrCreate()
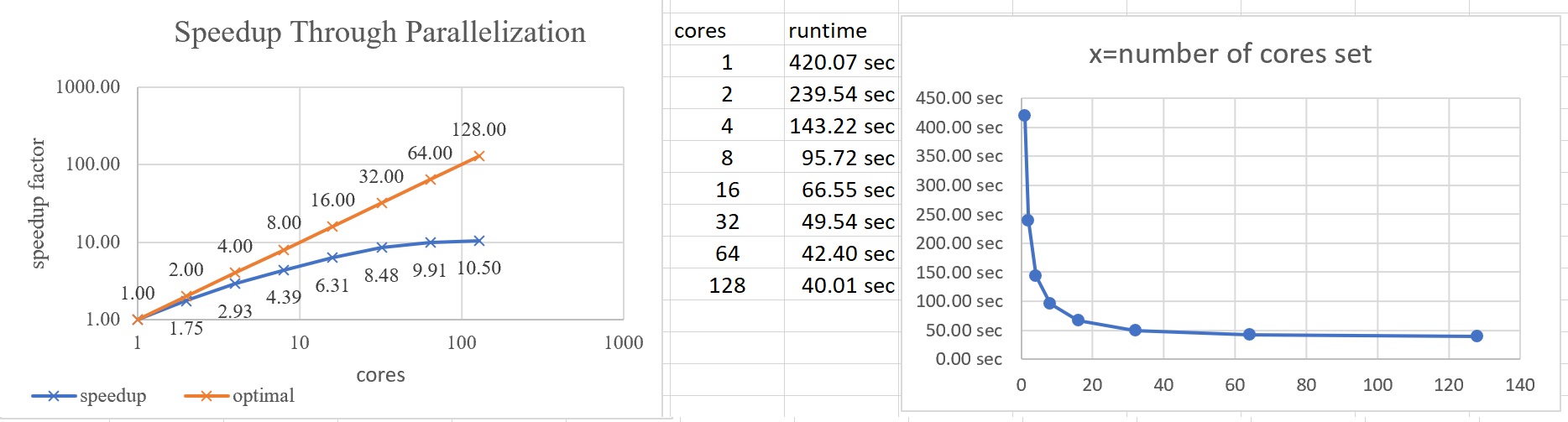
I do get a nice speed-up curve, but I can also see on htop, that the job is still using much more than one core.
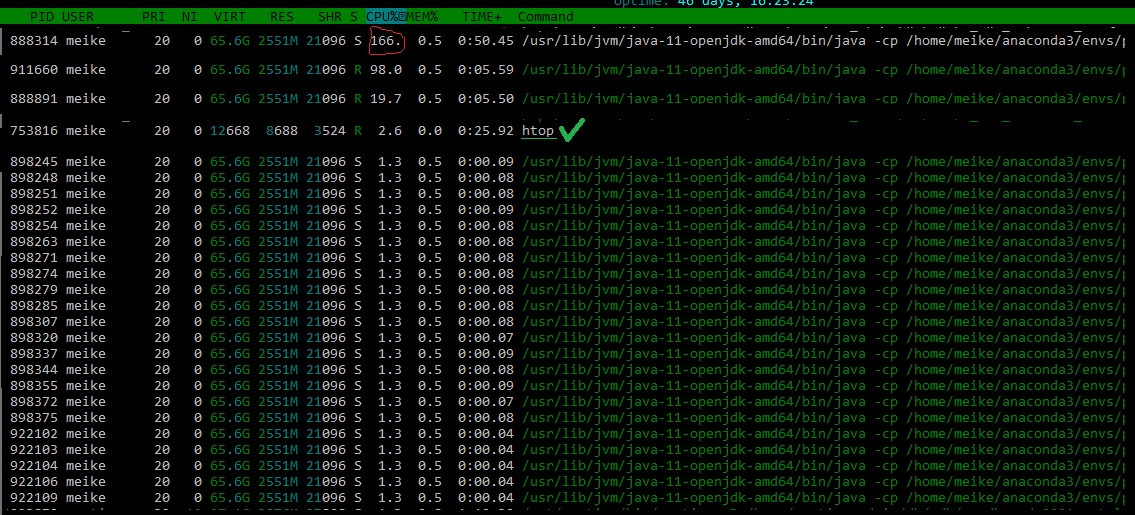
I'm running the spark job in a screen, and htop in a second terminal. That htop uses CPU is ok. but I don't understand why the topmost process still uses more than 100% of CPU. (100% is equivalent to one core fully used). Instead, this process sometimes goes up to 400%, in single-core setup. It doesn't seem right. also, there are several other processes popping up when I start the spark job, and they use a lot of CPU as well.
Does anyone have a suggestion on how I can force Spark to truly use one core?
and preferably not fan out over all of the cores (not ~1% usage on each, but 100% on one)
PS: Most important to limiting Spark so far seem to be the partitions. If they are set to default 200, Spark runs with full parallelization, even though it is told to use one core and one node...
CodePudding user response:
You may use the taskset command to limit a process to a single or multiple specified cores.
taskset -c 0 mycommand
-c, --cpu-list
Interpret mask as numerical list of processors instead of a
bitmask. Numbers are separated by commas and may include
ranges. For example: 0,5,8-11.
CodePudding user response:
When you create your spark session, you can set the number of cores when setting master, just pass local[1] instead of local, as follow:
spark = SparkSession.builder.master("local[1]")
Sets the Spark master URL to connect to, such as "local" to run locally, "local[4]" to run locally with 4 cores, or "spark://master:7077" to run on a Spark standalone cluster.