I have a confusion of the lazy load on Spark while using spark.read.json.
I have the following code:
df_location_user_profile = [
f"hdfs://hdfs_cluster:8020/data/*/*"
]
df_json = spark.read.json(json_data_files)
While the JSON data on HDFS is partitioned by year and month (year=yyyy, month=mm) and I want to retrieve all data of that dataset.
For this code block, I only read data from the defined location and there are no actions is executed. But I found on the Spark UI the following stage with giant input data.
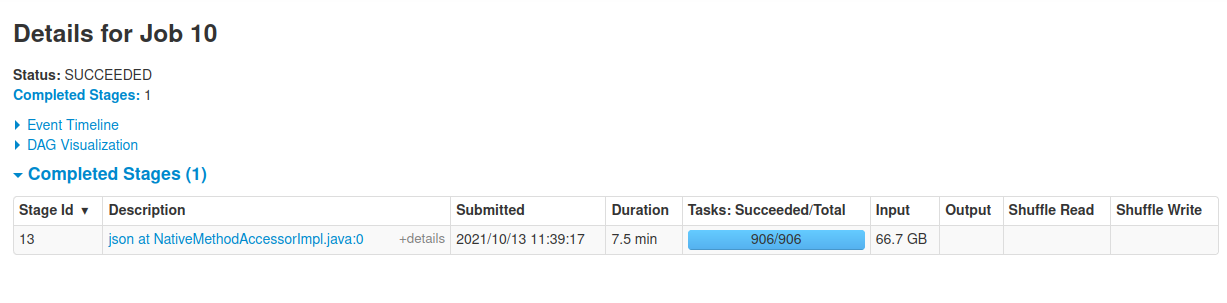
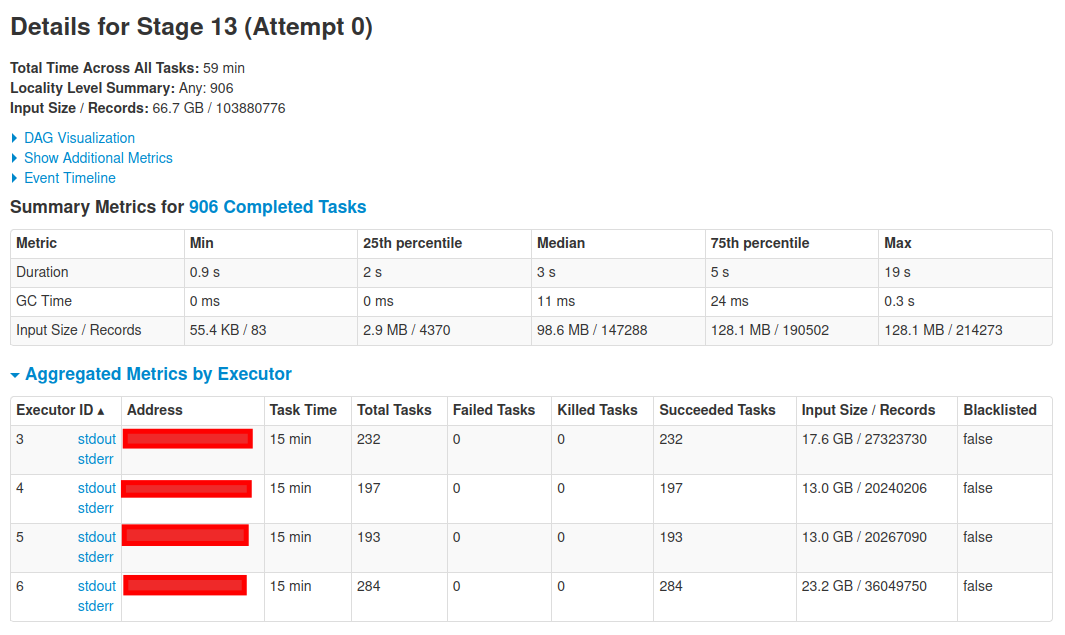
As I understand, the lazy load fashion of Spark will not read data until an action is called. Then this makes me confused.
After that, I call the count() action then the new stage is created and Spark read data again.
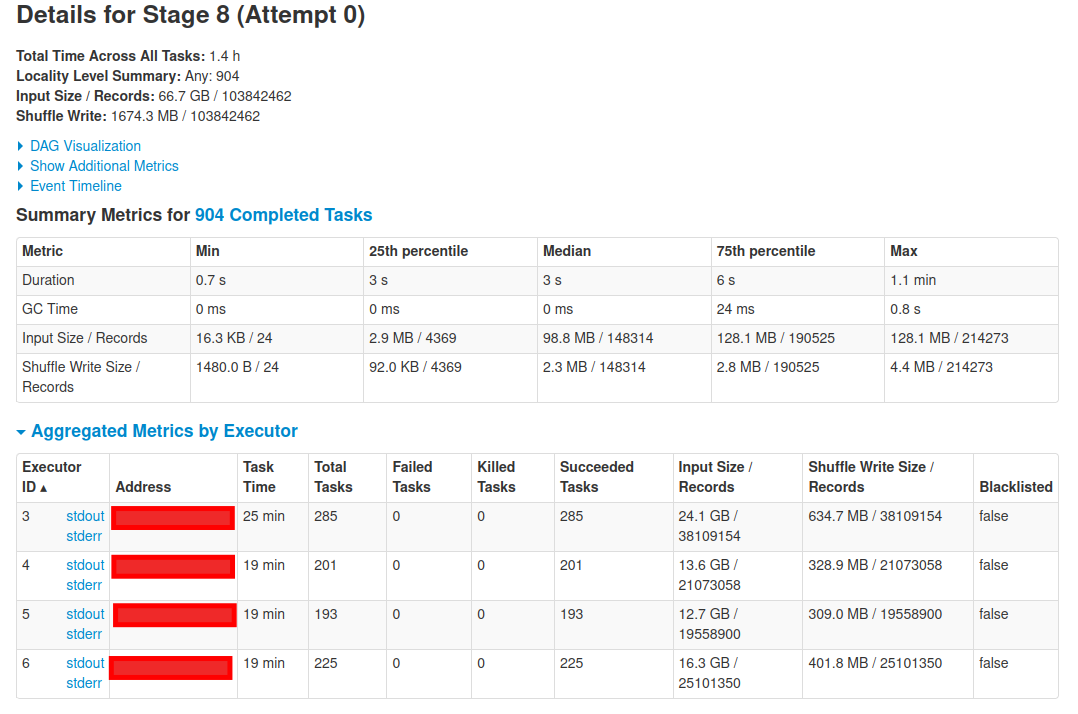
My question is why does Spark read data when no action is called (on the first job, stage)? How can I optimize this?
CodePudding user response:
It is doing a pass to evaluate the schema as it was not supplied. Aka infer schema.