It has been a long time that I dealt with pandas library. I searched for it but could not come up with an efficient way, which might be a function existed in the library.
Let's say I have the dataframe below:
df1 = pd.DataFrame({'V1':['A','A','B'],
'V2':['B','C','C'],
'Value':[4, 1, 5]})
df1
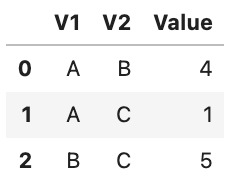
And I would like to extend this dataset and populate all the combinations of categories and put its corresponding value as exactly the same.
df2 = pd.DataFrame({'V1':['A','B','A', 'C', 'B', 'C'],
'V2':['B','A','C','A','C','B'],
'Value':[4, 4 , 1, 1, 5, 5]})
df2

In other words, in df1, A and B has Value of 4 and I also want to have a row of that B and A has Value of 4 in the second dataframe. It is very similar to melting. I also do not want to use a for loop. I am looking for a more efficient way.
CodePudding user response:
Use:
df = pd.concat([df1, df1.rename(columns={'V2':'V1', 'V1':'V2'})]).sort_index().reset_index(drop=True)
Output:
V1 V2 Value
0 A B 4
1 B A 4
2 A C 1
3 C A 1
4 B C 5
5 C B 5
CodePudding user response:
Or np.vstack:
>>> pd.DataFrame(np.vstack((df1.to_numpy(), df1.iloc[:, np.r_[1:-1:-1, -1]].to_numpy())), columns=df1.columns)
V1 V2 Value
0 A B 4
1 A C 1
2 B C 5
3 B A 4
4 C A 1
5 C B 5
>>>
For correct order:
>>> pd.DataFrame(np.vstack((df1.to_numpy(), df1.iloc[:, np.r_[1:-1:-1, -1]].to_numpy())), columns=df1.columns, index=[*df1.index, *df1.index]).sort_index()
V1 V2 Value
0 A B 4
0 B A 4
1 A C 1
1 C A 1
2 B C 5
2 C B 5
>>>
And index reset:
>>> pd.DataFrame(np.vstack((df1.to_numpy(), df1.iloc[:, np.r_[1:-1:-1, -1]].to_numpy())), columns=df1.columns, index=[*df1.index, *df1.index]).sort_index().reset_index(drop=True)
V1 V2 Value
0 A B 4
1 B A 4
2 A C 1
3 C A 1
4 B C 5
5 C B 5
>>>
CodePudding user response:
You can use methods assign and append:
df1.append(df1.assign(V1=df1.V2, V2=df1.V1), ignore_index=True)
Output:
V1 V2 Value
0 A B 4
1 A C 1
2 B C 5
3 B A 4
4 C A 1
5 C B 5