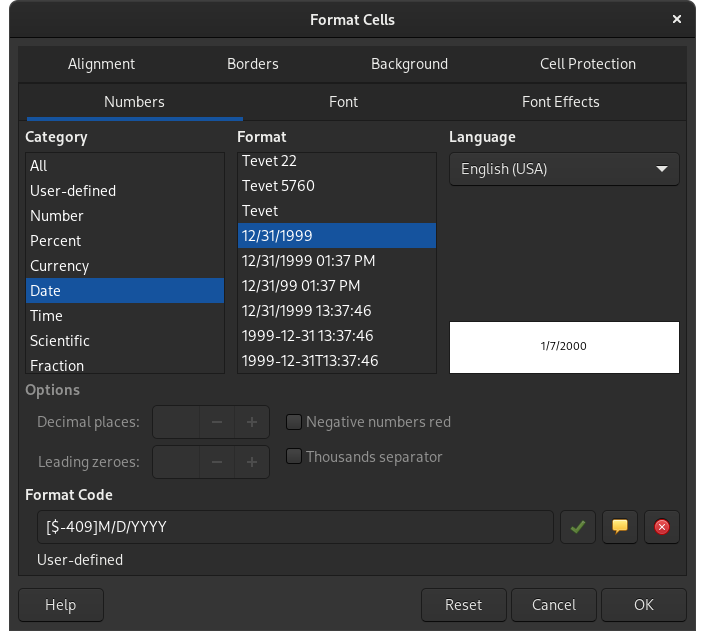
I read an excel file from a URL and need to do some cleaning before I can save it. In the original excel file, there are some logos and null entries in the first few rows and then the real data starts. The column date (Unnamed 0:) in excel file appears as date but when read into pandas for some reason it is converted to number. Using astype and pd.to_datetime converts the column to date but incorrect date. Any advice?
note: although date column appears as date in excel sheet, its type is general. I can go and manually change the type first in the excel file but I do not want to do that because I want to automate the process.
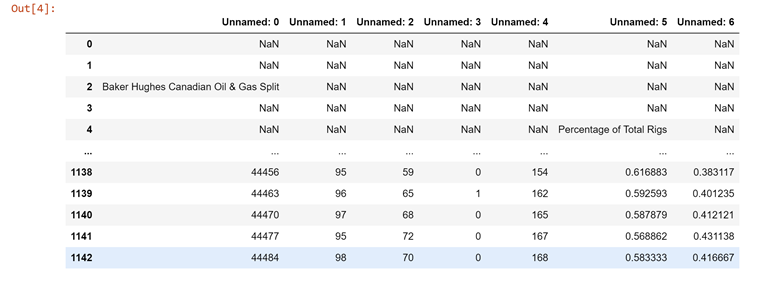
if you want to produce data, here is the code:
from requests import get
import pandas as pd
url = 'http://rigcount.bakerhughes.com/static-files/55ff50da-ac65-410d-924c-fe45b23db298'
# make HTTP request to fetch data
r = get(url)
# check if request is success
r.raise_for_status()
# write out byte content to file
with open('out.xlsb', 'wb') as out_file:
out_file.write(r.content)
Canada_Oil_Gas = pd.read_excel('out.xlsb', sheet_name='Canada Oil & Gas Split', engine='pyxlsb')
CodePudding user response:
The problem is caused by the cell format