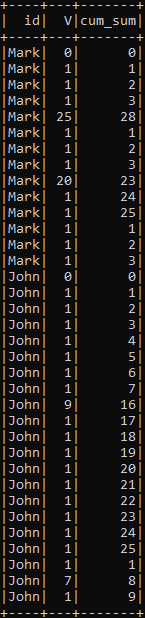
I have a dataframe shown below. I want to compute the cumulative sum for each id on V such that when the cumulative of the previous row is greater or equal to the threshold of 25, the cumulative sum will reset to current value as seen in the image below. I have tried writing a user-defined to operator on V but I received an error which says the it is not iterable. I tried you lag but I was not successful either. I need help!
df = sqlContext.createDataFrame(
[('Mark', 0.0), ('Mark', 1), ('Mark', 1),
('Mark', 1), ('Mark', 25), ('Mark', 1),
('Mark', 1),('Mark', 1),('Mark', 20),
('Mark', 1),('Mark', 1),('Mark', 1),
('Mark', 1),('Mark', 1),('John', 0),
('John', 1),('John', 1),('John', 1),
('John', 1),('John', 1),('John', 1),
('John', 1),('John', 9),('John', 1),
('John', 1),('John', 1),('John', 1),
('John', 1),('John', 1),('John', 1),
('John', 1),('John', 1),('John', 1),
('John', 7),('John', 1)],
('id', "V"))
CodePudding user response:
Maybe there is a prettier faster way, this will work but isn't efficient. Windows are expensive (memory) to use. If you are going to use this in production be wary. If speed is required a custom udf used with a window might be a little faster than this to avoid the double windowing:
val df = Seq(("Mark", 0), ("Mark", 1), ("Mark", 1),
("Mark", 1), ("Mark", 25), ("Mark", 1),
("Mark", 1),("Mark", 1),("Mark", 20),
("Mark", 1),("Mark", 1),("Mark", 1),
("Mark", 1),("Mark", 1),("John", 0),
("John", 1),("John", 1),("John", 1),
("John", 1),("John", 1),("John", 1),
("John", 1),("John", 9),("John", 1),
("John", 1),("John", 1),("John", 1),
("John", 1),("John", 1),("John", 1),
("John", 1),("John", 1),("John", 1),
("John", 7),("John", 1)).toDF("id","V")
val windowSpecLag = Window.partitionBy("id").orderBy("id")
val windowSpec = Window.partitionBy("id").orderBy("id").rowsBetween(Window.unboundedPreceding,Window.currentRow )
// add a running sum to the window
val divis = df.withColumn("sum",sum("V").over(windowSpec)).withColumn("divis",floor(col("sum")/25))
// shift around the numbers so the math works as desired
val lagged = divis.withColumn("clag", (lag("divis", 1, 0) over windowSpecLag) )
//re-run running total on newly partitioned data
val windowSpecFixed = Window.partitionBy("id","clag").orderBy("id","clag").rowsBetween(Window.unboundedPreceding,Window.currentRow )
lagged.withColumn("runningTotalUnder25",sum("V").over(windowSpecDivis)).show(100)
If you wanted to do this efficiently, I'd probably try and reframe the problem so I could use group by. Or change the way the data is defined.