I want to find the content inside the following tag:
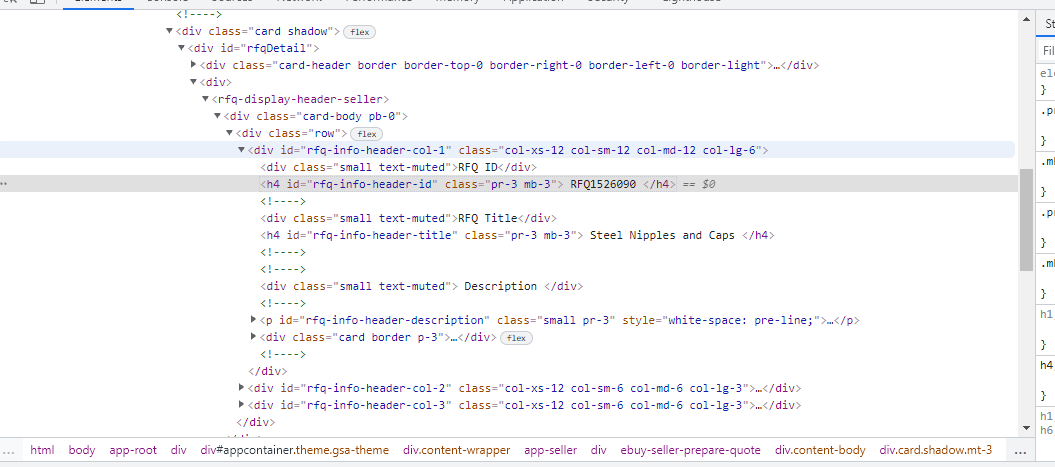
<h4 id="rfq-info-header-id" class="pr-3 mb-3">
RFQ1526090
</h4>
Full code:
<rfq-display-header-seller>
<div class="card-body pb-0">
<div class="row">
<div id="rfq-info-header-col-1" class="col-xs-12 col-sm-12 col-md-12 col-lg-6">
<div class="small text-muted">RFQ ID</div>
<h4 id="rfq-info-header-id" class="pr-3 mb-3">
RFQ1526090
</h4>
I tried:
rfq_id = [tag.text.strip() for tag in soup.find_all(name='h4', attrs={'id': 'rfq-info-header-id','class': 'pr-3 mb-3'})]
print(rfq_id)
But this resulted in empty list [].
Is this because the h4 tag is inside many tags? How to simplify the code to extract the data inside tag in the above code
CodePudding user response:
I'm getting output as follows:
from bs4 import BeautifulSoup
html_doc="""
<rfq-display-header-seller>
<div >
<div >
<div id="rfq-info-header-col-1" >
<div >RFQ ID</div>
<h4 id="rfq-info-header-id" >
RFQ1526090
</h4>
"""
soup = BeautifulSoup(html_doc, 'html.parser')
# rfq_id = soup.find('h4').text
# print(rfq_id)
rfq_id = [t.get_text(strip=True) for t in soup.find_all('h4')]
print(rfq_id)
Output:
['RFQ1526090']
Output using only find method:
RFQ1526090