I am trying to create a script to scrape price data from Udemy courses. I'm struggling with navigating the HTML tree because the element I'm looking for is located inside multiple nested divs.
here's the structure of the HTML element I'm trying to access:
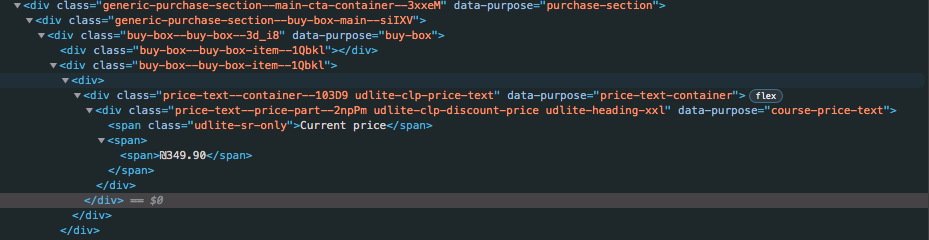
what I tried:
response = requests.get(url)
print(response)
doc = BeautifulSoup(response.text, "html.parser")
parent_div = doc.find(class_="sidebar-container--purchase-section--17KRp")
print(parent_div.find_all("span"))
and even:
response = requests.get(url)
print(response)
doc = BeautifulSoup(response.text, "html.parser")
main = doc.find(class_="generic-purchase-section--main-cta-container--3xxeM")
title = main.select_one("div span span span")
Here’s the URL: https://www.udemy.com/course/the-complete-web-development-bootcamp/
tried searching all the spans in the HTML and the specific span I'm searching for doesn't appear maybe because it's nested inside a div?
would appreciate a little guidance!
CodePudding user response:
The price is being loaded by JavaScript. So it is not possible to scrape using beautifulsoup.
The data is loaded from an API Endpoint which takes in the course-id of the course.
Course-id of this course:
1565838
You can directly get the info from that endpoint like this.
import requests
course_id = '1565838'
url= f'https://www.udemy.com/api-2.0/course-landing-components/{course_id}/me/?components=price_text'
response = requests.get(url)
x = response.json()
print(x['price_text']['data']['pricing_result']['price'])
{'amount': 455.0, 'currency': 'INR', 'price_string': '₹455', 'currency_symbol': '₹'}
CodePudding user response:
I tried your first approach several times and it works more-or-less for me, although it has returned a different number of span elements on different attempts (10 is the usual number but I have seen as few as 1 on one occasion):
import requests
from bs4 import BeautifulSoup
url = 'https://www.udemy.com/course/the-complete-web-development-bootcamp/'
response = requests.get(url)
doc = BeautifulSoup(response.text, "html.parser")
parent_div = doc.find(class_="sidebar-container--purchase-section--17KRp")
spans = parent_div.find_all("span")
print(len(spans))
for span in spans:
print(span)
Prints:
10
<span data-checked="checked" data-name="u872-accordion--3" data-type="radio" id="u872-accordion-panel--4" style="display:none"></span>
<span ></span>
<span >Subscribe</span>
<span>Try it free for 7 days</span>
<span >$29.99 per month after trial</span>
<span ></span>
<span data-checked="" data-name="u872-accordion--3" data-type="radio" id="u872-accordion-panel--6" style="display:none"></span>
<span ></span>
<span >Buy Course</span>
<span >30-Day Money-Back Guarantee</span>
As afar as your second approach goes, your main div does not have that many nested span elements, so it is bound to fail. Try just one span element:
import requests
from bs4 import BeautifulSoup
url = 'https://www.udemy.com/course/the-complete-web-development-bootcamp/'
response = requests.get(url)
doc = BeautifulSoup(response.text, "html.parser")
main = doc.find(class_="generic-purchase-section--main-cta-container--3xxeM")
title = main.select_one("div span")
print(title)
Prints:
<span >30-Day Money-Back Guarantee</span>