I am importing data from a machine that has thousands of cycles on it. Each cycle lasts a few minutes and has two peaks in pressure that I need to record. One example can be seen in the graph below.
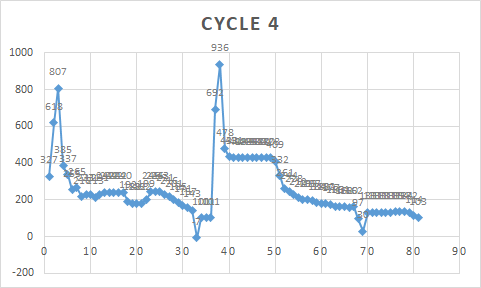
In this cycle you can see there are two peaks, one at 807 psi and one at 936 psi. I need to record these values. I have sorted the data so i can determine when a cycle is on or off already, but now I need to figure out how to record these two maxes. I previouly tried this:
df2 = df.groupby('group')['Pressure'].nlargest(2).rename_axis (index=['group', 'row_index'])
to get the maxes, but realized this will only give me the two largest values which in some cycles happen right before the the peak.
In this example dataframe I have provided one cycle:
import pandas as pd
data = {'Pressure' : [100,112,114,120,123,420,123,1230,1320,1,23,13,13,13,123,13,123,3,222,2303,1233,1233,1,1,30,20,40,401,10,40,12,122,1,12,333]}
df = pd.DataFrame(data)
The peak values for this should be 1320, and 2303 whilke ignoring the slow increase to these peaks.
Thanks for any help!
(This is also for a ton of cycles, so i need it to be able to go through and record the peaks for each cycle)
CodePudding user response:
Alright, I had a go, using the simple heuristic I suggested in my comment.
def filter_peaks(df):
df["before"] = df["Pressure"].shift(1)
df["after"] = df["Pressure"].shift(-1)
df["max"] = df.max(axis=1)
df = df.fillna(0)
return df[df["Pressure"] == df["max"]]["Pressure"].to_frame()
filter_peaks(df) # test one application
If you apply this once to your test dataframe, you get the following result:

You can see, that it almost doesn't work: the value at line 21 only needed to be a little higher for it to exceed the true second peak at line 8.
You can get round this by iterating, ie., with filter_peaks(filter_peaks(df)). You then do end up with a clean dataframe that you can apply your .nlargest strategy to.
EDIT Complete code example:
import pandas as pd
data = {'Pressure' : [100,112,114,120,123,420,123,1230,1320,1,23,13,13,13,123,13,123,3,222,2303,1233,1233,1,1,30,20,40,401,10,40,12,122,1,12,333]}
df = pd.DataFrame(data)
def filter_peaks(df):
df["before"] = df["Pressure"].shift(1)
df["after"] = df["Pressure"].shift(-1)
df["max"] = df.max(axis=1)
df = df.fillna(0)
return df[df["Pressure"] == df["max"]]["Pressure"].to_frame()
df2 = filter_peaks(df) # or do it twice if you want to be sure: filter_peaks(filter_peaks(df))
df2["Pressure"].nlargest(2)
Output:
19 2303
8 1320
Name: Pressure, dtype: int64