I have the following data set from Douglas Montgomery's book Introduction to Time Series Analysis & Forecasting:
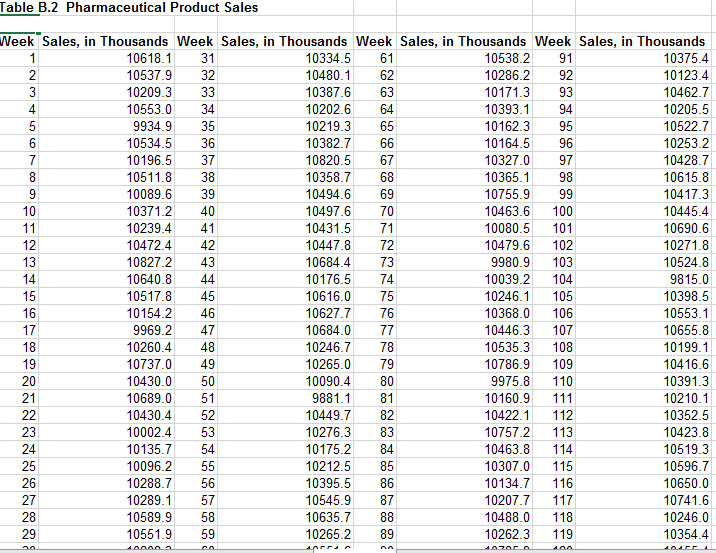
I created a data frame called pharm from this spreadsheet. We only have two variables but they're repeated over several columns. I'd like to take all odd "Week" columns past the 2nd column and stack them under the 1st Week column in order. Conversely I'd like to do the same thing with the even "Sales, in thousands" columns. Here's what I've tried so far:
pharm2 <- data.frame(week=c(pharm$week, pharm[,3], pharm[,5], pharm[,7]), sales=c(pharm$sales, pharm[,4], pharm[,6], pharm[,8]))
This works because there aren't many columns, but I need a way to do this more efficiently because hard coding won't be practical with many columns. Does anyone know a more efficient way to do this?
CodePudding user response:
If the columns are alternating, just subset with a recycling logical vector, unlist and create a new data.frame
out <- data.frame(week = unlist(pharm[c(TRUE, FALSE)]),
sales = unlist(pharm[c(FALSE, TRUE)]))
CodePudding user response:
You may use the seq function to generate sequence to extract alternating columns.
pharm2 <- data.frame(week = unlist(pharm[seq(1, ncol(pharm), 2)]),
sales = unlist(pharm[seq(2, ncol(pharm), 2)]))