I have a large dataframe that consitsts of many cycles, each cycle has 2 maximum peak values inside that I need to capture into another dataframe.
I have created a sample data frame that mimics the data I am seeing:
import pandas as pd
data = {'Cycle':[1,1,1,1,1,1,1,1,1,1,2,2,2,2,2,2,2,2,2,2,3,3,3,3,3,3,3,3,3,3], 'Pressure':[100,110,140,180,185,160,120,110,189,183,103,115,140,180,200,162,125,110,196,183,100,110,140,180,185,160,120,180,201,190]}
df = pd.DataFrame(data)
As you can see in each cycle there are two maxes but the part I was having trouble with was that the 2nd peak is usaully higher than the first peak, so there could be rows of numbers technicially higher than the other peaks max in the cycle. The results should look something like this:
data2 = {'Cycle':[1,1,2,2,3,3], 'Peak Maxs': [185,189,200,196,185,201]}
df2= pd.DataFrame(data2)
I have tried a couple methods including .nlargest(2) per cycle, but the problem is that since one of the peaks is usually higher it will pull the 2nd highest number in the data, which isnt necesssarily the other peak.
This graph shows the peak pressures from each cycle that I would like to be able to find.
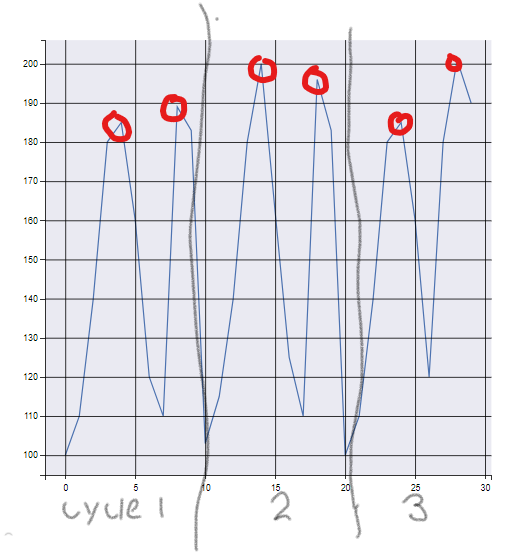
Thanks for any help.
CodePudding user response:
From scipy argrelextrema
from scipy.signal import argrelextrema
out = df.groupby('Cycle')['Pressure'].apply(lambda x : x.iloc[argrelextrema(x.values, np.greater)])
Out[124]:
Cycle
1 4 185
8 189
2 14 200
18 196
3 24 185
28 201
Name: Pressure, dtype: int64
out = out.sort_values().groupby(level=0).tail(2).sort_index()
out
Out[138]:
Cycle
1 4 185
8 189
2 14 200
18 196
3 24 185
28 201
Name: Pressure, dtype: int64
CodePudding user response:
Use groupby().shift() to get the neighborhood values, then compare:
g = df.groupby('Cycle')
local_maxes = (df['Pressure'].gt(g['Pressure'].shift()) # greater than previous row
& df['Pressure'].gt(g['Pressure'].shift(-1))] # greater than next row
)
df[local_maxes]
Output:
Cycle Pressure
4 1 185
8 1 189
14 2 200
18 2 196
24 3 185
28 3 201