I am working on a data frame, which consists of the name of company, the ticker id, as well as the ticker exchange id. The code for scraping the data works fine. Below is the output of the data.
Company name (Company symbol, Company exchange)
0 Abbott Laboratories (ABT, NYQ)
1 ABBVIE (ABBV, NYQ)
2 ASML.AS (ASML.AS, AMS)
3 AD.AS (AD.AS, AMS)
Index(['Company name', ('Company symbol', 'Company exchange')], dtype='object')
type(df_companies)= pandas.core.frame.DataFrame
I have tried to strip the redundant symbols (), with codes like:
df[df_companies.columns] = df_companies.apply(lambda x: x.str.strip())
df_companies.applymap(lambda x: x.strip() if isinstance(x, str) else x)
These codes didn't work, they resulted in NaN. I tried to transpose the data frame, but that didn't help as well. The idea is to create the df_companies like this:
Company name Company symbol Company exchange
0 Abbott Laboratories ABT NYQ
1 ABBVIE ABBV NYQ
2 ASML.AS ASML.AS AMS
3 AD.AS AD.AS AMS
The final idea is to create a list per exchange, like this:
NYQ=['ABT', 'ABBV']
AMS=['ASMl.AS', 'AD.AS']
Any idea on how to solve this issue?
CodePudding user response:
you can use groupby to aggregate another column to a list
data = {
"Company exchange": ["NYQ", "NYQ", "AMS", "AMS"],
"Company Symbol" : ["ABT", "ABBV", "ASML.AS", "AD.AS"]
}
df = pd.DataFrame(data)
print(df)
output :
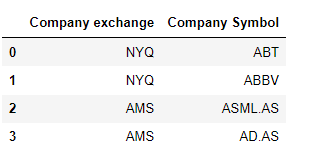
df.groupby('Company exchange')['Company Symbol'].apply(list)
output:

CodePudding user response:
You can first remove the () brackets from your symbol/exchange column, and then Series.str.split on , with expand=True:
df[['Company Symbol','Company Exchange']] = df['(Company symbol, Company exchange)'].str.strip('()')\
.str.split(',',expand=True)
df.drop('(Company symbol, Company exchange)',axis=1,inplace=True)
Which gives:
Company name Company Symbol Company Exchange
0 Abbott Laboratories ABT NYQ
1 ABBVIE ABBV NYQ
2 ASML.AS ASML.AS AMS
3 AD.AS AD.AS AMS
And lastly:
>>> df.groupby('Company Exchange')['Company Symbol'].agg(list)
Company Exchange
AMS [ASML.AS, AD.AS]
NYQ [ABT, ABBV]
Sample df:
>>> df.to_dict()
{'Company name': {0: 'Abbott Laboratories',
1: 'ABBVIE',
2: 'ASML.AS',
3: 'AD.AS'},
'(Company symbol, Company exchange)': {0: '(ABT, NYQ)',
1: '(ABBV, NYQ)',
2: '(ASML.AS, AMS)',
3: '(AD.AS, AMS)'}}
Please check the last code below:
df.columns = [str(s).replace('(','').replace(')','').replace("'",'') for s in df.columns]
df[['Company Symbol','Company Exchange']] = pd.DataFrame(df["Company symbol, Company exchange"].tolist(), index=df.index)
df.drop("Company symbol, Company exchange",axis=1,inplace=True)
df.groupby('Company Exchange')['Company Symbol'].agg(list)
CodePudding user response:
From your DataFrame :
>>> data = {
... "Company name": ["Abbott Laboratories", "ABBVIE", "ASML.AS", "AD.AS"],
... "(Company symbol, Company exchange)" : ["(ABT, NYQ)", "(ABBV, NYQ)", "(ASML.AS, AMS)", "(AD.AS, AMS)"]}
>>> df = pd.DataFrame(data)
>>> df
Company name (Company symbol, Company exchange)
0 Abbott Laboratories (ABT, NYQ)
1 ABBVIE (ABBV, NYQ)
2 ASML.AS (ASML.AS, AMS)
3 AD.AS (AD.AS, AMS)
We start to replace the () by [] to work with lists intead of tuples :
>>> df["(Company symbol, Company exchange)"] = df["(Company symbol, Company exchange)"].replace(to_replace='\(', value="[", regex=True)
>>> df["(Company symbol, Company exchange)"] = df["(Company symbol, Company exchange)"].replace(to_replace='\)', value="]", regex=True)
>>> df
Company name (Company symbol, Company exchange)
0 Abbott Laboratories [ABT, NYQ]
1 ABBVIE [ABBV, NYQ]
2 ASML.AS [ASML.AS, AMS]
3 AD.AS [AD.AS, AMS]
Now we can "explode" the data inside the brackets in two new columns :
>>> df[['Company symbol','Company exchange']] = pd.DataFrame(df["(Company symbol, Company exchange)"].apply(lambda x: x[1:-1].split(',')).tolist(), index= df.index)
>>> df
Company name (Company symbol, Company exchange) Company symbol Company exchange
0 Abbott Laboratories [ABT, NYQ] ABT NYQ
1 ABBVIE [ABBV, NYQ] ABBV NYQ
2 ASML.AS [ASML.AS, AMS] ASML.AS AMS
3 AD.AS [AD.AS, AMS] AD.AS AMS
To finish and get the expected result, we can use a groupby and get the wanted lists :
>>> df.groupby('Company exchange')['Company symbol'].apply(list)
Company exchange
AMS [ASML.AS, AD.AS]
NYQ [ABT, ABBV]
Name: Company symbol, dtype: object